About
![]()
The Shivering-Isles (SI) Infrastructure is the home infrastructure of Sheogorath. It’s a production infrastructure that runs various services including Instant Messenging, E-Mail but also multi-media services and hosting various websites.
The SI Infrastructure is aiming to be owned, private, cost efficient and flexible. In the current digital age, where everything and everyone wants to sell you Software as a Service with a subscription model, ownership has become a luxury. With advertisement, surveillance, and “AI” companies grabbing onto every aspect of the internet, it has become almost impossible to own data and keep them from prying eyes that want to make money or influence from it. In order to make this effort sustainable, the infrastructure has to be cost-efficent, with a major focus on runtime cost, making sure that supporting the infrastructure is viable in long term. To allow experimentation and multitude of use-cases, self-contained components compose the infrastructure, allowing experimentation and replacement.
This documentation provides some insight into the Shivering-Isles Infrastructure. Like every documentation of a living system, it’s incomplete and out-of-date.
Hardware
This is an overview of the hardware currently deployed.
The main goal of this section is to make it easy to refer to the currently used hardware without the need to repeat all the details over and over again.
Node
A node is a machine in the Cluster, this includes control-plane and compute nodes. In the current setup these are the same, there is the possibility, that they will become more divers in the long run.
Parts
| Part | Type | Reasoning |
|---|---|---|
| “Lenovo ThinkCentre M75q Gen 2” | CPU, RAM, board, NVMe, Chassis, power supply, … | These machines, are quite powerful, have a low energy footprint, are easy to maintain and are relatively quiet. Note: There is a AMD Ryzen 4xxx and a 5xxx variant of this device, I highly recommend to get the 5xxx series. |
| Crucial 3200MHz DDR4 Memory | RAM | The M75q already comes with 16GB of DDR4 memory pre-installed, an additional 16GB Stick provides a total of 32GB of RAM and switches RAM into dual channel mode. |
| Crucial mx500 2TB SATA-SSD | SSD | In order to provide storage within the cluster, some additional NVMe Space in combination with a CSI is very useful. |
Setup
In order to setup the device, install the additional RAM in the underside of the device and the SSD in the 2.5“ bay.
Power usage
In my usage of these machines, my tests resulted in a power-usage of 20W on average, however, they can peak notably higher, when full performance is required. Given they run on a 65W power supply, there is this “natural” limit.
Cost
Before buying this hardware there was an estimate, that compared it with the potential cloud spend on Hetzner cloud for machines with acceptable to comparable specs.
To make them comparable the M75q’s storage of 512GiB was used as reference and all Hetzner Machines were “filled up” to 512GiB with Hetzner storage volumes.
Further for local electricity cost it was assumes that 1 kWh would cost 0.35€ and that the average power usage per machine would be 14 watts, there was a running cost added of 5€ to upgrade the home internet connection and further 5€ to run a load-balancer in a cloud to connect the machines as described in the Ingress-Termination concept.
This calculation assumes a target of 3 hosts of the same type to build a Kubernetes Cluster with shared costs for the loadbalancer and the internet cost, while electricity cost is per node.

NAS
The Network Attached Storage (NAS) is a device, that run an own processor and a bunch of disk (either SSDs or HDDs) and provides them as generic storage to other devices on a network.
In this case the NAS exists to provide bulk storage, as well as a local backup location for (important) data.
Parts
| Part | Type | Reasoning |
|---|---|---|
| “Terra-master F4-423” | board, processor, chassis and power supply | It’s provides some nice hardware, with x86_64 processor in it, which allows to install an OS like TrueNAS on it. |
| 16GB of 2666MHz DDR4 RAM | RAM | By default, the Terramaster only ships with 4GB, which is way to little for TrueNAS. 16GB because that’s the max supported by the processor according to Intel. |
| 2x Crucial P2 250GB NVMe | NVMe | The original intend was to put ZIL and L2ARC on this drive, but currently the drives just host the TrueNAS OS. |
| 4x 6TB WD Red Plus drives | HDD | These drives provide the bulk storage for the NAS and are rated as NAS drives without SMR. |
Setup
To install the additional parts, you’ll have to open up the chassis. Then install the new RAM kit and NVMes as shown in the video below. Be aware, that you have to replace the already installed RAM module, which is not easily accessible. In order to reach it, you’ll either need to remove the 4 screws visible on the board, where you install the NVMe or reach with your finger to the backside of the board.
Further, in order to install TrueNAS, I recommend to remove the pre-installed USB drive from Terramaster installed on the inner side, that contains the Terramaster OS, unplug it and store it, in case you want to send back the device.
Operating System
While originally the NAS was running TrueNAS Core in it, it was switched to TrueNAS Scale in order to benefit from the automated certificate Management in TrueNAS Scale and run on Let’s Encrypt certificates.
A good tutorial on how to setup pools:
Power usage
In my tests with no, but just test workload, the average power usage of this NAS was 31W idle using TrueNAS Core, with peaks during usage to up to 39W when having disk activity. During boot up there were some further peaks, I didn’t record any further. There is a “natural” boundary of 90w due to the included power supply.
Disk Replacement
When a disk fails, it should be replaced. To replace a disk it’s important to locate the correct one. It’s advised to write down the disk’s serial number and it’s physical slot of the NAS. Since the TerraMaster NAS has no indicator LED, it’s only possible to locate the drive in TrueNAS using ls -l /dev/disk/by-path otherwise.
Before adding the disk to the pool, run a SMART test of the type conveyance to check for issues from shipping.
A short tutorial about the steps in TrueNAS can be found here:
Alternatively, here is the official upstream documentation.
Opinions on when to replace drives
When it comes to replacing disks over time, there are multiple options available. Some survey and opinions on the topic have been collected on Mastodon.
UPS
The Uninterruptible Power Supply (UPS) is a battery buffered power plug. It help to cover short energy outages as well as providing over current protection to devices behind it. As a bonus, it also provides some metrics, which can be used to measure the overall power draw of devices attached.
Parts
| Part | Type | Reasoning |
|---|---|---|
| “APC Back-UPS 850VA” | UPS | It’s a relatively cheap and simple UPS. Does its job and provides enough capacity to keep everything running for roughly 20 minutes. |
Setup
The UPS provides 8 sockets in total, 6 of them are battery buffered and provide overcurrent protection, the remaining two only have overcurrent protection.
The current layout with the UPS’ power cord leaving at the bottom.
| Left | Right |
|---|---|
| empty | NAS |
| empty | infra power socket (Nodes, network, …) |
| empty | empty |
| empty | Office tools (Notebook, Monitors, …) |
There went no further thought in the arrangement beyond: Laptops have their own battery and when the monitors turn of, it won’t hurt. Everything else should continue to operate.
The UPS itself is connected using a USB to serial cable to the USB-Port of the NAS, which distributes the state of the UPS over using “Network UPS Tools” (NUT) and is monitored using nut-exporter, which is running in the Kubernetes cluster.
Power usage
The is currently no measurement for the power usage of the UPS itself. Device that are battery buffered are currently using between 100 and 120 watts of power according to stats collected with nut-exporter.
Operating System
After running 2 years on Fedora Server, the Shivering-Isles infrastructure has migrated to Talos Linux as host OS.
The benefits of using Talos Linux over Fedora as host OS underneath Kubernetes, are divers, starting from the immutable nature of the OS along with the stronger SecureBoot features, due to using UKI with an easy to use setup-keys mechanism. It also drops the need to build the container runtime and kubernetes packages ourselves. Finally Talos has a very minimal OS approach comparable to Google’s ContainerOS.
This of course means that some features are lost, like Cockpit support and SELinux.
Talos Linux
Talos is a container optimized Linux distro; a reimagining of Linux for distributed systems such as Kubernetes. Designed to be as minimal as possible while still maintaining practicality. For these reasons, Talos has a number of features unique to it.
Talos is managed using the Talos API, which is very similar and partitially integrated with the Kubernetes API. It’s used for the initial setup and future node management.
In the Shivering-Isles infrastructure, Talos is managed with a tool called talhelper which provides the needed ability to have the operating system definition declarative.
Node and Kubernetes upgrades are done using the system-upgrades-controller.
Finally to make up for the lack of SELinux, Talos provides hardened defaults and additionally gVisor as container runtime.
Some important factors for using Talos over other OSes were:
- modern software versions
- TPM-based LUKS encryption
- gvisor support
- automated updates
- No SSH / non-kubernetes access to the node
- Purpose built for Kubernetes
Concepts
Just a short section to explain some concepts and their adoption in the Shivering-Isles Infrastructure. The goal is write original documentation for the Shivering-Isles infrastructure instead of copying existing content. The Shivering-Isles documentation links to upstream documentation instead.
GitOps
The Shivering-Isles Infrastructure uses GitOps as central concept to maintain the Kubernetes cluster and deploy changes to production. Centralising around git as Single Source of Truth without dynamic state provides an easier way to verify changes. It also reduces the amount of trust put into the CI system by enforcing signed commits on the GitOps operator side.
The current tool of choice to implement GitOps in the Shivering-Isles Infrastructure is FluxCD in combination with a monorepo.
GitOps Security
To secure GitOps based deployments and reduce the risks of compromise, the GitOps deployment in the Shivering-Isles Infrastructure only accepts signed commits. This prevents a deployment of workload if an attackers mananges to push a commit onto the GitOps repository. The git forge itself is in charge of preventing rollbacks in the commit history. Rollbacks could be prevented by using git tags instead of git branches as reference, but are less practical.
Further all secrets stored in the GitOps repository are encrypted using SOPS along with insensitive, but irrelevant information, such as dns names.
Local testing
It has proven to be useful to pre-render certain aspects of the GitOps deployments before pushing them.
To render kustomizations locally this command can be used:
kubectl kustomize ./path/to/kustomization --load-restrictor LoadRestrictionsNone
To improve debugging, the relevant top-level kustomization can be exteded with:
buildMetadata:
- originAnnotations
- managedByLabel
- transformerAnnotations
See the upstream documentation for details.
Releases
The Shivering-Isles infrastructure has monthly releases of the GitOps repository. These have no functional purpose but rather function as a log of what has been accomplished in the past month.
Reviewing this progress provides a good sense on how much is done in a month, without necessarily noticing it. It also shows how well update automation works based on the deps commits.
Tooling
To generate the release notes, git-chglog is used with a custom configuration, adding some emojis and categorising the semantic commits.
The GitLab release CLI creates the final releases in GitLab. This also create git tags and generates the version number as part of a release pipeline.
Site Reliability Engineering
Site reliability engineering (SRE) is a set of principles and practices that applies aspects of software engineering to IT infrastructure and operations.
In the Shivering-Isles Infrastructure various apps have an own set of SLOs to validate for service degradation on changes. It’s also a good practice for SRE in other environments.
Besides maintaining reasonable SLOs, other SRE practices are implemented, such as post mortems and especially the practice of reducing toil. All components of the infrastructure have a maintenance budget, if it’s depleted, it’s time to fix the apps or get rid of it.
Service Level Objectives
All public facing apps and infrastructure components should have an Service Level Objective (SLO). The most basic SLOs for web apps are the availability and latency measured through the ingress controller. An examples for an SLO definitions is the Shivering-Isles blog.
Apps that provide more insight via metrics, can have app-specific SLOs to optimise for user impacting situations, that aren’t covered by basic web metrics. An example is the sidekiq SLO for Mastodon.
The actual objectives in the Shivering-Isles infrastructure are often relatively low around 95 percent.
Self-Hosted Timebudget
Additional to your traditional error budget, for the Shivering-Isles Infrastructure there is self-hosted time budget. This is the acceptable amount of time per month to be spend on maintainence. The timebudgets are set for individual software as well as the entire infrastructure.
If the budget is reached or exceeded, work on anything new is halted and work focusses to
- improving deployment processes,
- replace hard to maintain software or
- move it out of self-hosting.
This makes sure that self-hosting doesn’t become a timecreep while keeping software up-to-date.
Incident Response
Aiming for SRE best practices in the home infrastructure, larger outages and other incidents should be acompanied by a post mortem, helping to improve the infrastructure and resolve sources for incidents permanently.
The post mortem template used for this is inspired by the SRE book.
Even if never finished or published, the post mortem helps to structure ideas and the situation itself. Making incident response much more thorough.
Learning about SRE
A good start is this small video Series by Google:
Further there is the Google SRE book as recommended read.
Further there are some good talks from SREcon:
Monitoring
The Shivering-Isles Infrastrcture provides various services and tries to achieve a good Service Level. To validate the achievement of these service Levels, internal and external monitorings systems constantly check the status of the system and notify administrators if something goes wrong.
Since monitoring systems are supposed to notify about outages, it’s important that they continue to function during outages. While also keeping costs in check.
The overall setup
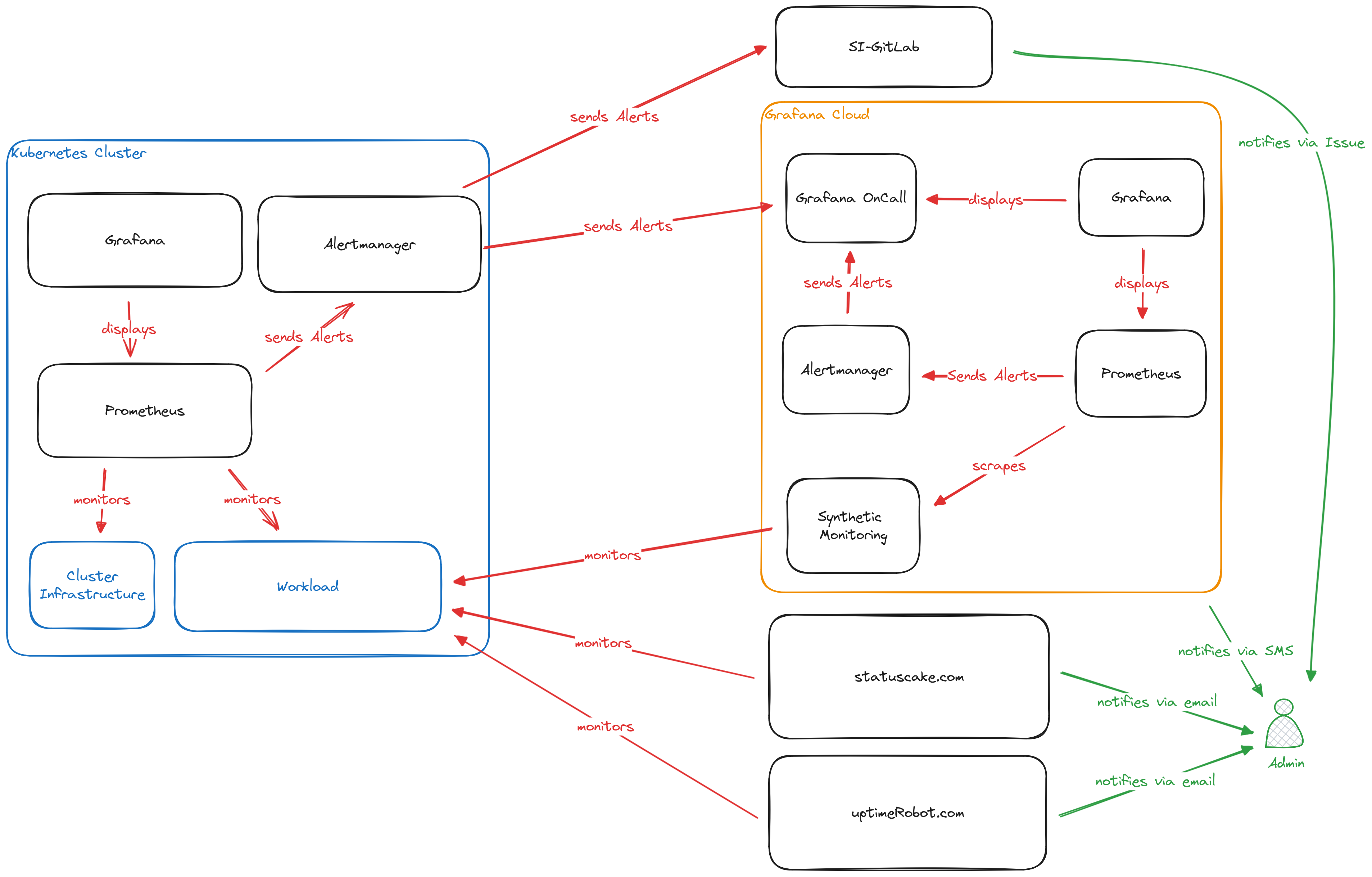
The Shivering-Isles infrastructure monitoring is split between internal and external monitoring.
For internal monitoring the kube-prometheus-stack is used and provides insights into all running applications and overall cluster health.
External monitoring uses a multituide of providers to regularly check the availabilty of externally available services such as the Shivering-Isles Blog or Microblog.
Internal Monitoring
The internal monitorings is defined using the prometheus-operator resources such as ServiceMonitors or PodMonitors in combination with PrometheusRules.
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: example
namespace: example
spec:
selector:
matchLabels:
app: example
namespaceSelector:
matchNames:
- example
endpoints:
- port: metrics
---
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: example
namespace: example
labels:
app.kubernetes.io/name: example
spec:
selector:
matchLabels:
app.kubernetes.io/name: example
podMetricsEndpoints:
- port: metrics
---
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: example
namespace: example
spec:
groups:
- name: example
rules:
- alert: ExampleAlert
annotations:
description: Very examplish Alert that will trigger for some reason. Just ignore it, it's just an example.
summary: Examplish Alert, please ignore.
expr: absent(prometheus_sd_discovered_targets{config="serviceMonitor/example/example/0"})
for: 10m
labels:
issue: Just ignore it, it's just an example.
severity: info
To view metrics and details, an internal Grafana instance exists that provides Dashboards, that are directly created from configmaps along with the applications.
Finally there is an alert Manager that sends all critical alerts off to the external systems as well as keeping a hearthbeat with the external Alertmanager to make sure the cluster monitoring is still functional and the SI-GitLab to open issues for critical alerts, so they aren’t missed.
External Monitoring
The external Monitoring is setup across various external systems. Most importantly Grafana Cloud, but also StatusCake and UptimeRobot.
UptimeRobot, StatusCake and Synthetic Monitoring
UptimeRobot, StatusCake and Synthetic Monitoring are cloud service that allow to send Requests to public endpoints and measure the results from various locations in an interval. Providing external visibility for the infrastructure.
In the Shivering-Isles Infrastructure this monitoring allows to validate external connectivity indepentent of the internal monitorings. This is especially important since the Ingress Termination allows externally available services to be fully available, while being at home, while external connectivity is interrupted. This is not a theoretical scenario, it has taken place many times in the past.
UptimeRobot and StatusCake send their outage reports via E-Mail.
SI-GitLab
GitLab runs outside the home infrastructure on an external VPS. This makes it independent of the home infrastructure and just keeps track of issues send by the internal alertmanager.
Grafana Cloud Alertmanager and Prometheus
Besides Synthetic Monitoring, which is already discussed in a previous section, Grafana Cloud also provides internal Prometheus instances, which isn’t used for anything that the metrics of the Synthetic Monitoring. It is acompanied by an Alertmanager that is triggered by Prometheus alerts, when Synthetic Monitoring reports outages of websites and services.
Grafana OnCall
Grafana OnCall is the center for all critical alerts. It monitors the Grafana Cloud Alertmanager as well as the Alertmanager running in the Kubernetes cluster for hearthbeats. Further the Alertmanagers forward critical alerts to the OnCall instance which then triggers an escalation to notify an Admin via SMS and the Grafana OnCall app about outages.
This is particularly relevant, since the SI-Infrastructure also runs mailserver which can and do become unavailable. This prevents UptimeRobot and StatusCake from reporting outages.
SLOs and SLAs
Topics around SLOs and SLAs are described in the SRE-section
Runbooks
Part of the Monitoring is explaining alerts and provide helpful insights for a response. This is done in runbooks. For the Shivering-Isles Infrastructure runbooks are self-hosted.
Ingress Termination
The Shivering-Isles Infrastructure, given it’s a local-first infrastructure has challenges to optimise traffic flow for local devices, without breaking external access.
TCP Forwarding
A intentional design decision was to avoid split DNS. Given that all DNS is hosted on Cloudflare with full DNSSEC integration, as well as running devices with active DoT always connecting external DNS Server, made split-DNS a bad implementation.
At the same time, a simple rerouting of all traffic to the external IP would also be problematic, as it would require either a dedicated IP address or complex source-based routing to only route traffic for client networks while allowing VPN traffic to continue to flow to the VPS.
The solution most elegant solution found was to reroute traffic on TCP level. Allow high volume traffic on port 443 to be rerouted using a firewall rule, while keeping the remote IP identical and not touching any VPN or SSH traffic in the process.
A request for the same website looks like this:
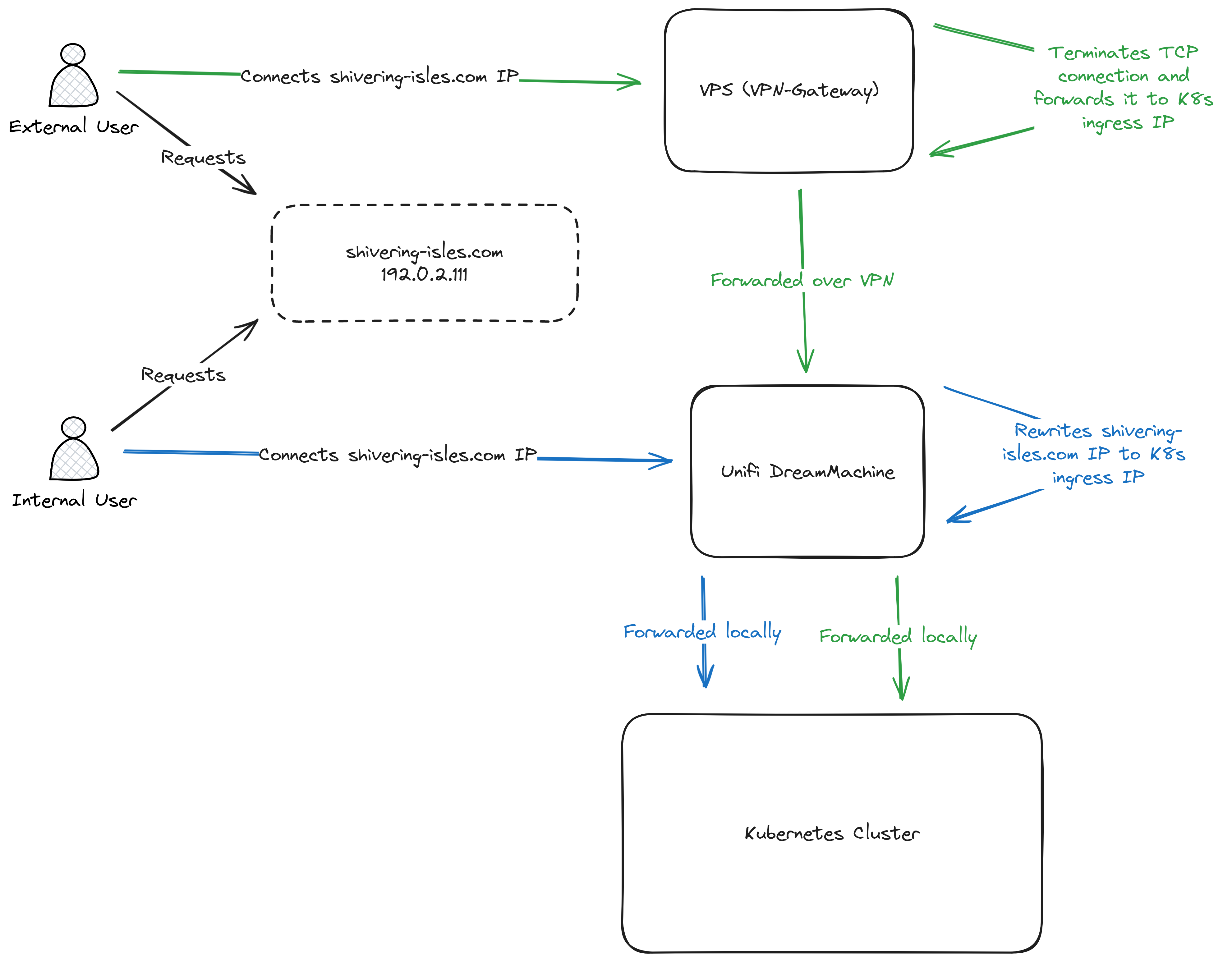
In both cases the connections are terminated on the Kubernetes Cluster. The external user reaches the VPS and is then rerouted over VPN. The local user is rerouted before the connection reaches the internet, resulting in keeping all traffic locally.
Since only TCP connections are forward at any point all TLS termination takes place on the Kubernetes cluster regardless.
Setting up local redirects
In order to redirect traffic in Kubernetes, the services with external connectivitly get the IPs of the external loadbalancer as externalIPs in the kubernetes services.
On the UDM as well as other clients on the same subnet as the Kubernetes cluster, the following script is used (assuming internal-k8s.example.com external-k8s.example.com as targets):
#!/bin/sh
TARGET_DNS="external-k8s.example.com"
DESTINATION_DNS="internal-k8s.example.com"
TARGET_IP="$(nslookup "$TARGET_DNS" | grep 'Address:' | tail -1 | sed -e 's/Address: //g')"
DESTINATION_IP="$(nslookup "$DESTINATION_DNS" | grep 'Address:' | tail -1 | sed -e 's/Address: //g')"
iptables -t nat -A PREROUTING --destination "$TARGET_IP" -p tcp --dport 443 -j DNAT --to-destination "$DESTINATION_IP:443"
iptables -t nat -A OUTPUT --destination "$TARGET_IP" -p tcp --dport 443 -j DNAT --to-destination "$DESTINATION_IP:443"
Preserving source IP addresses
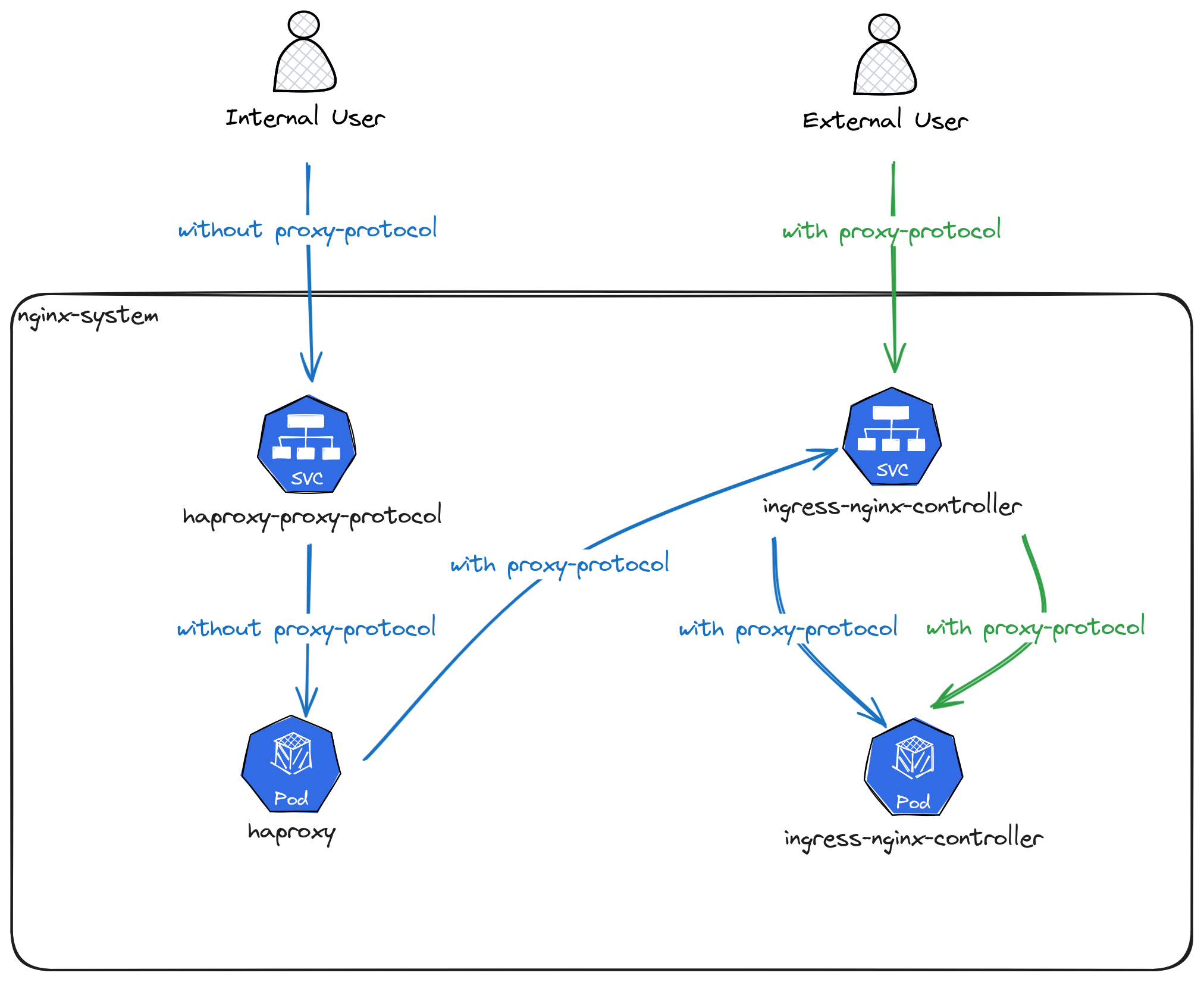
On the VPS, the TCP connection is handled by an HAProxy instance that speaks proxy-protocol with the Kubernetes ingress service.
On the Unifi Dream Machine it’s a simple iptables rule, which redirects the traffic. In order to also use proxy-protocol with the ingress service, it’s actually redirected to an HAProxy running in the Kubernetes cluster besides the ingress-nginx. This is mainly due to the limitation in ingress-nginx that doesn’t allow mixed proxy-protocol and non-proxy-protocol ports without using custom configuration templates.
Software Lifecycle
In the Shivering-Isles infrastructure a certain pattern for software deployments emerged.
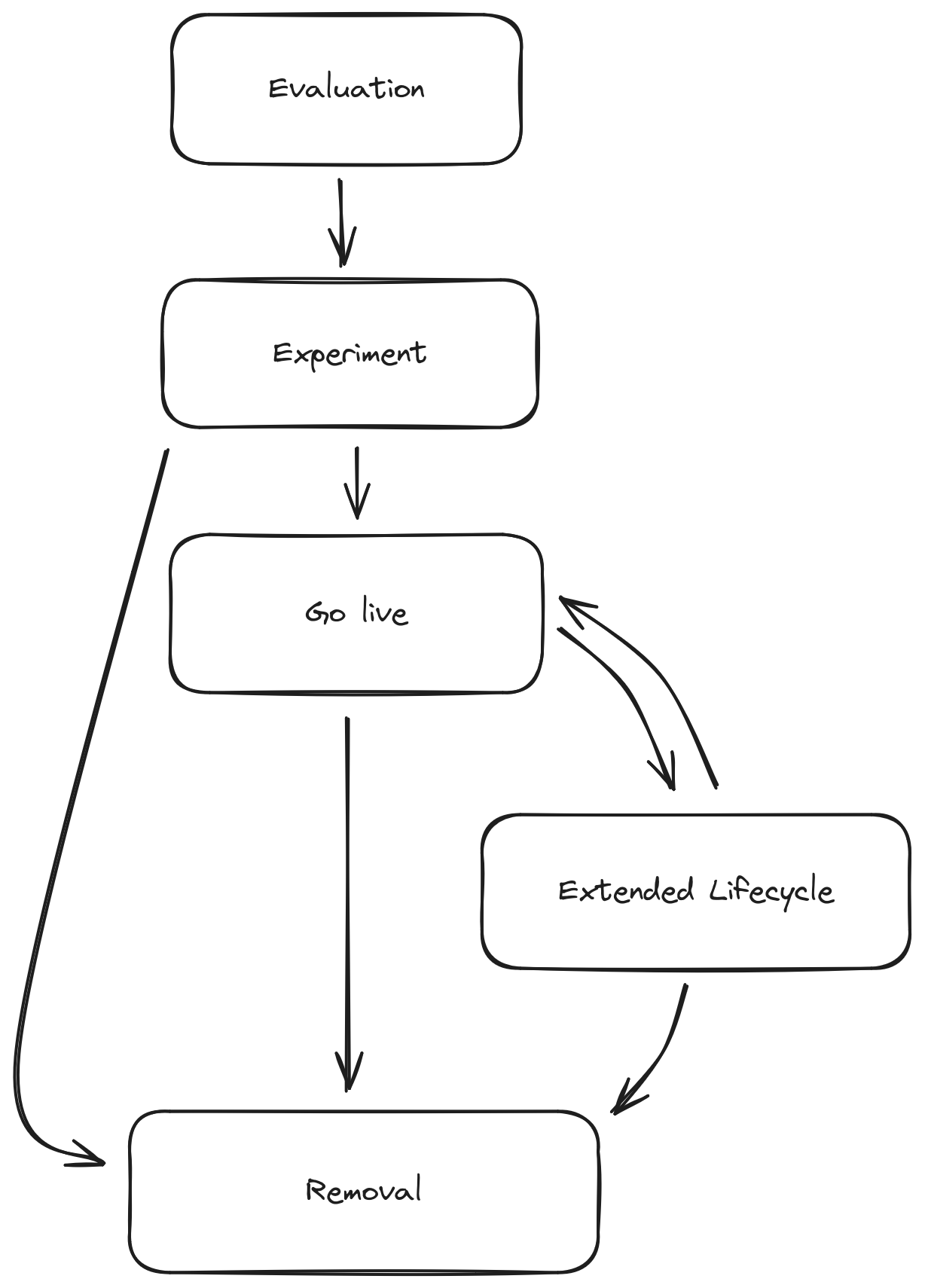
Evaluation
Before starting with deployment of a piece of software there is a lot of reading going on. The documentation and project is examined for certain criteria and options like
- container images,
- Helm Charts,
- Kustomizations,
- integration with existing operators (PostgreSQL and Redis),
- OIDC capability,
- release cycle and
- general community.
Experimenting
With a first examination a PoC is deployed on the K8s cluster. Usually limited to the intranet if not even limited to the namespace itself. The ergonmic of deploying the software is checked and the basic setup is developed.
Going live
After testing the Software, it might be reinstalled or the test deployment get adopted by adding the relevant manifests to the gitops repository and harding the setup with the proper network policies, serviceaccount permissions and restrictions on the namespace.
From here renovate is configured to automate software updates and help with creating Merge Requests that make maintence easy.
Extended lifecycle
When a software is supposed to be replaced but might still provide some important functionality, that isn’t fully replaced yet, the software is limited to the intranet and added an oauth2-proxy to prevent unauthorized access from outside. This drastically reduces the risk for the setup and allows to fall behind with updates, while mitigating the easiest attacks.
Removal
At the end, the software is removed from the cluster by deleting the manifests from the gitops repository. This will also delete the namespace. Potentially remaining backups can be manually deleted after a while out of sync with the software.
This completes the software lifecycle.
Power Consumption
As part of hardware testing and usage, it’s important to keep an eye on the power consumption of devices. Since a major cost doesn’t originate from buying the hardware but from running it.
With the Shivering-Isles Infrastructure the devices run in a regular flat without additional, external cooling, therefore it’s enough to measure the power consumption of the device itself.
Measuring power consumption
A Shelly Plug S measures the power consumption. It reports measurements down to 1W accuracy over time. The time of measurement is usually a long time frame, such as 7 days, to collect realistic numbers under regular use.
The goal is to collect realistic data for the actual use-case and not some benchmark results that either collect minimums or maximums.
After the measurement removing the Shelly Plug eliminates the additional power consumption and an unneeded factor for failure.
Monitoring power consumption
If the device runs on the UPS, the UPS itself reports a load statistic which allows the calculation of the power consumption of all battery buffered devices. The way Prometheus monitors the overall use of power for all devices attached to the UPS.
In the Shivering-Isles Infrastructure this is used to keep the overall power consumption in check and spot anomalies on regular reviews of the relevant dashboard.
For the UPS integration itself, nut-exporter is used.
Backup
In the Shivering-Isles infrastructure backups take place hourly to daily, depending on the amount of data and their importance.
What is the 3-2-1 Backup strategy?
The current backup concept uses a tiered principle.
- Basic snapshots in Longhorn are used to store data within the Kubernetes cluster for quickest recovery. Goal is to undelete data in case accidents happen. These snapshots take place hourly.
- Backups from Longhorn to Minio are used to create efficient block-storage based backups to a separate system. Minio uses a ZFS filesystem underneath as part of the TrueNAS setup. Goal is to keep data around independent of longhorn and making sure Volumes that are deleted can be recoved. These backups take place daily.
- TrueNAS ships encrypted backups to a remote storage location, usually a backup focussed cloud provider like Backblaze or Storj. Lifecycle rules, objectlocks and bucket versioning are used to manage data. Goal is to keep data around, in case the entire site is lost or a ransomware attack takes place and destroys data and backups. The Object Locks prevent deletion of data by attackers.
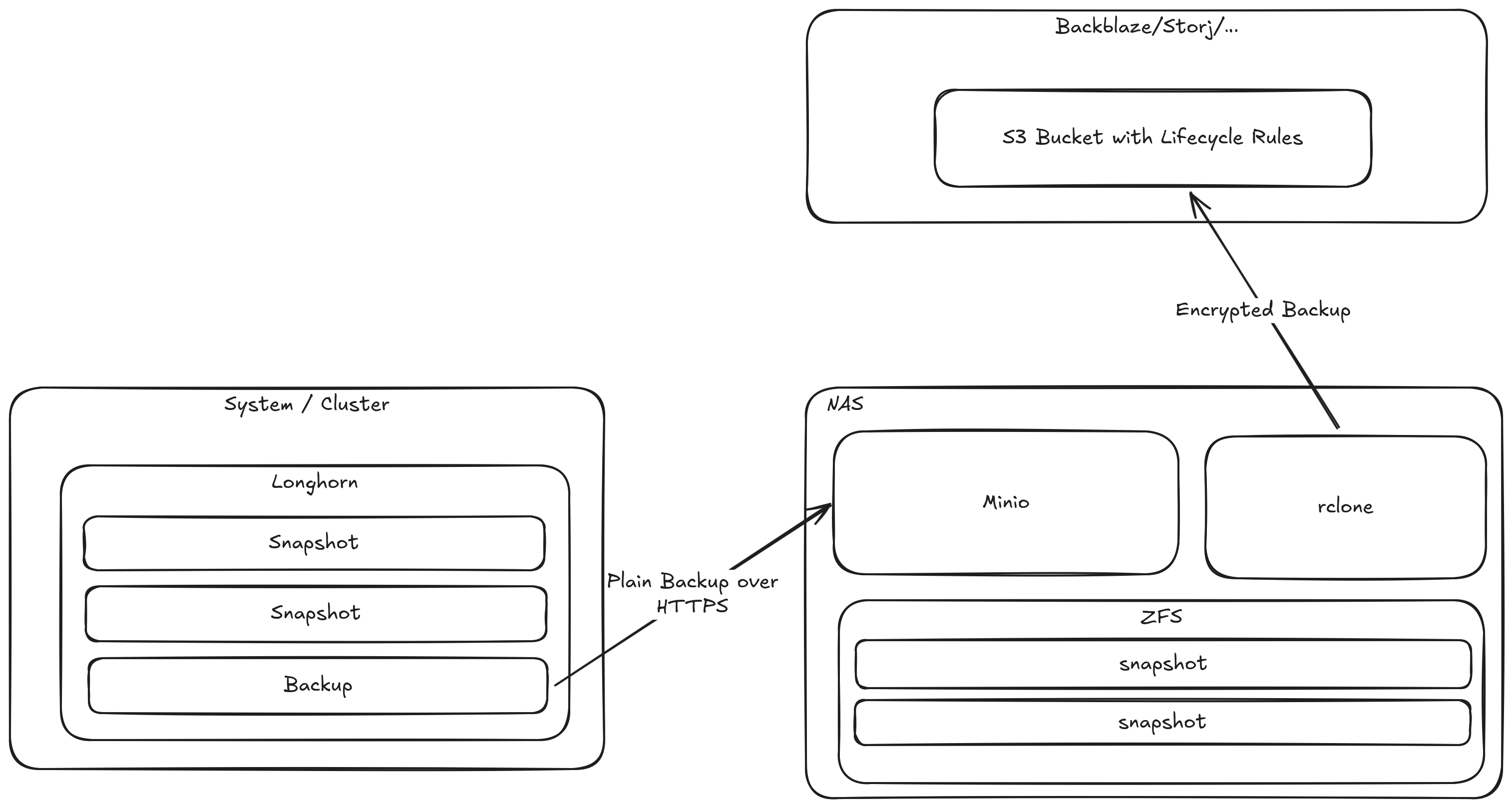
Verification of Backups and data
Currently there is no automatic restore test.
But for particularly important data, there is an implementation for data integrity monitoring, that ensure that photos don’t corrupt silently in the background until its too late.
This is intentionally independent of the application, to ensure, it catches potential mistakes by the app developers.
Apps
This category lists software that is used to provide Services around the Shivering-Isles infrastructure.
Ansteckschildchen
Ansteckschildchen is a German word for “badge” or “label”. It’s a mostly drop-in replacement for the static badges of shields.io.
It’s a toy project.
Links
Anubis
Anubis is a proof-of-work proxy that sits in front of web applications. Clients must solve a computational challenge before requests are forwarded to the upstream service, mitigating automated bots and DDoS attacks.
Links
Blog
The Shivering-Isles blog is a simple nginx image, that was infused with a built of the jekyll-based blog content.
Besides being a static blog, it also houses the .well-known directory, that handles the Web Key Directory for the Shivering-Isles. Additionally it delegates Matrix and Mastodon to their respective services, allowing to use shivering-isles.com as domain for user identities.
Links
Camo
Go-Camo is an image proxy that caches and serves remote images through the local server, providing access control via HMAC-signed URLs.
Links
CrowdSec
CrowdSec is a modern implementation of Fail2Ban with some additional bells and whistles.
It allows usage of a centralised API that collect and distributes community (and comercial) blocklists that people can subscribe to. This allows to share insights and a broader view for malicious IPs based on behaviour collected from millions of production and honeypot systems.
As fail2ban, crowdsec collects data by parsing logs and triggering actions based on that. It provides a multitude of actions, such as banning, trigering a captcha or throttling traffic. What actions are actually used depends on remedation components.
In the Shivering-Isles infrastructure CrowdSec is used in local-mode only with a local-API (lapi) server hosted on Kubernetes and remidation components deployed on all remote and entry systems.
The Security engine is fed by Loki, utilising the centralised logging capabilities, reducing the amount of software and privileges that need to be deployed.
Links
Draupnir
Draupnir is a Matrix moderation bot that helps manage abuse, spam, and governance in Matrix rooms and communities.
Usage
In the Shivering-Isles infrastructure Draupnir is deployed as a bot called @gatekeeper:shivering-isles.com and takes care of moderating rooms run by Sheogorath.
Links
Find my Device
“Find My Device” (FMD) is a self-hosted backend of the Find-My-Device Android app, that allows you to utilise similar features to the Find-My-Device apps from Apple or Google, like logging your phone’s location or remotely locking or wiping it, without being in need to surrender these valuable data to one of these companies.
Links
Forecastle
Forecastle is a app dashboard integrated with Kubernetes allowing Ingress Resources to be added to the dashboard using a few annotations.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
#…
annotations:
forecastle.stakater.com/expose: "true"
forecastle.stakater.com/appName: Example app
forecastle.stakater.com/group: Example Group
forecastle.stakater.com/icon: https://icon.example.com/image.jpg
This provides easy overview over all the Shivering Isles applications. Using oauth2-proxy access to the dashboard is restricted to authenticated users.
Links
GitLab Runner
GitLab Runner executes CI/CD jobs from GitLab repositories on the Kubernetes cluster.
Links
Harbor
Harbor is a container registry with the ability to act as pull-through proxy for external registries. In the Shivering-Isles Infrastructure Harbor is mainly used as pull-through proxy for all upstream registries.
It’s configured as mirror in podman, crio and containerd.
Known issues
- Doesn’t work well with custom-error-pages in ingress-nginx.
nginx.ingress.kubernetes.io/custom-http-errors: "418"solved this.
Links
Immich
Immich is a self-hosted backup solution for photos and videos on mobile device.
This kustomization provide a basic setup for an immich instance on Kubernetes. For a functional setup, there are some components you have to implement yourself:
There are components used in the SI-Infrastructure, but they rely on operators that might not fix your setup.
You can also overwrite configs globally using a optional secret called immich-env-override.
Be aware that you might need to adjust some configs, like the IMMICH_MACHINE_LEARNING_URL if you use the kustomize prefix or suffix features.
Usage
Create a kustomization.yaml in your gitops setup:
# kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: immich
resources:
- https://git.shivering-isles.com/shivering-isles/infrastructure-gitops//apps/base/immich?ref=main
- ingress.yaml
components:
- https://git.shivering-isles.com/shivering-isles/infrastructure-gitops//apps/base/immich/postgres-zalando?ref=main
- https://git.shivering-isles.com/shivering-isles/infrastructure-gitops//apps/base/immich/redis-spotahome?ref=main
Add an ingress.yaml and add the components for postgres and redis.
Deploy it all using your GitOps toolchain.
Origin
This kustomization has drawn quite some inspiration from the upstream helm chart, but allows easier overwrites and replacements and doesn’t rely on a abstracted helm chart.
This switch makes it easier to integrate Operator-based components and adjustments.
Links
Apps
Jellyfin
Jellyfin is the volunteer-built media solution that puts you in control of your media. Stream to any device from your own server, with no strings attached. Your media, your server, your way.
— jellyfin.org
In the Shivering-Isles Infrastructure Jellyfin provides the media platform for streaming series and alike from the local NAS. Replacing services like Netflix for enjoying TV-Shows and Movies ripped from good old DVDs and Bluerays.
Jellyfin itself is integrated with the Kubernetes cluster its running on using the Jellyfin PDB Manager, that automatically configures the Pod Disruption Budget of the Jellyfin Pod to disallow disruptions while something is playing, to make sure maintenance work does not interfere with the watching experience.
Links
Apps
Keycloak
In the Shivering-Isles Infrastructure Keycloak is the central identity provider. It allows users to manage their sessions and provides Multi-Factor authentication for all services.
The Keycloak instance is usually referred to as “SI-Auth”. The Shivering-Isles realm contains the user-base. The Keycloak system realm, called “Master,” administrates the Shivering-Isles realm.
While the Shivering-Isles realm is accessible over the internet, allowing easy access and authentication from everywhere in the world, the “master” realm is only accessible through the local-network administration endpoint. This reduces the risk of a take over, even if an attacker compromises credentials.
Authentication configuration
To allow Multi-Factor-Authentication (MFA) a copy of the web browser flow was adjusted to account for WebAuthn and TOTP-based MFA.
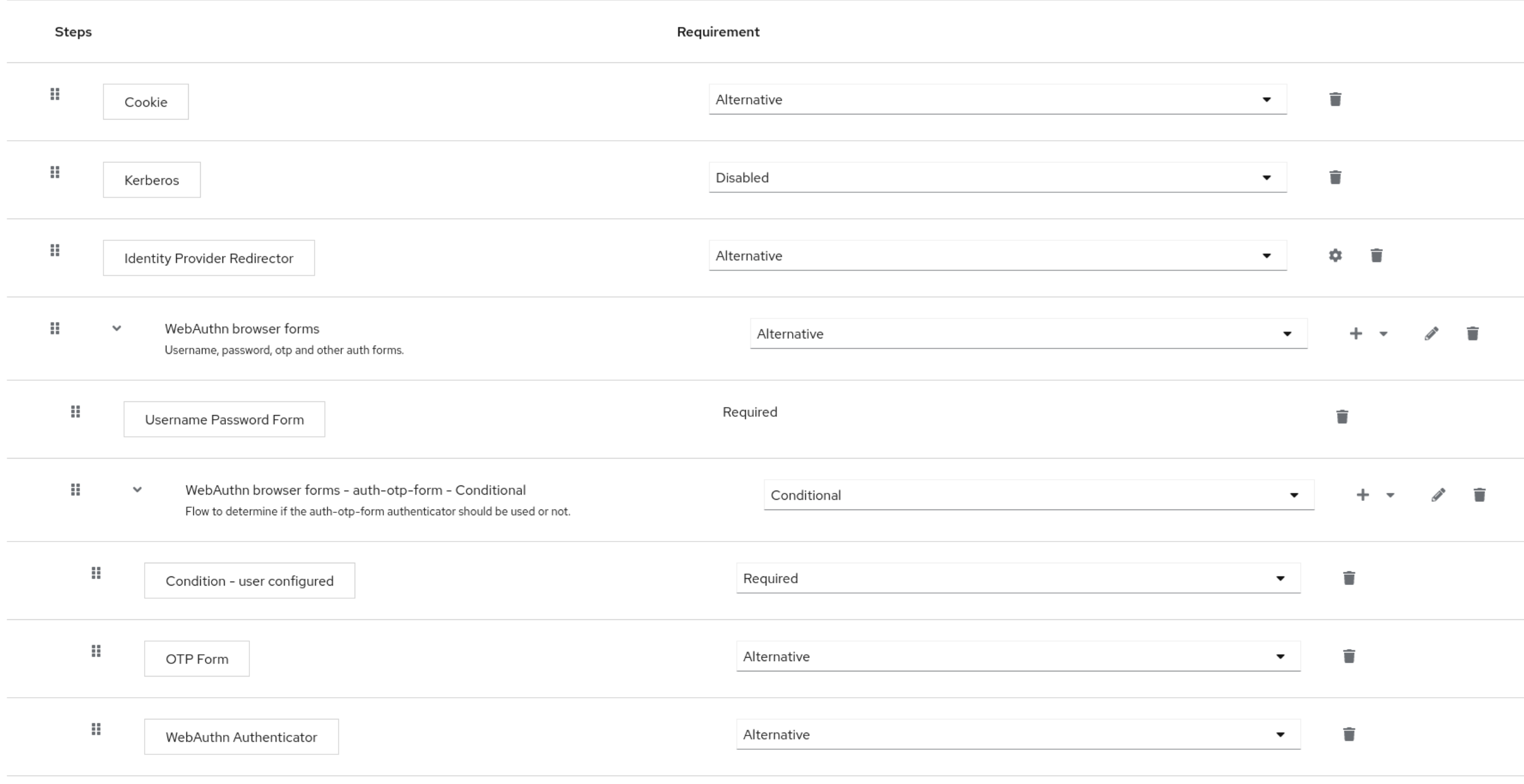
The official Keycloak documentation describes the basics to set up WebAuthn as MFA flow.
While Passwordless authentication is prepared to be rolled out, some experimentation showed that the authentication flow becomes too complex.
For some apps, like Paperless, there is also an adjusted authentication flow using step-up authentication. This helps to enforce authentication in shorter periods of time, making it easy to keep SSO sessions long, while privileged access has much shorter authentication windows.
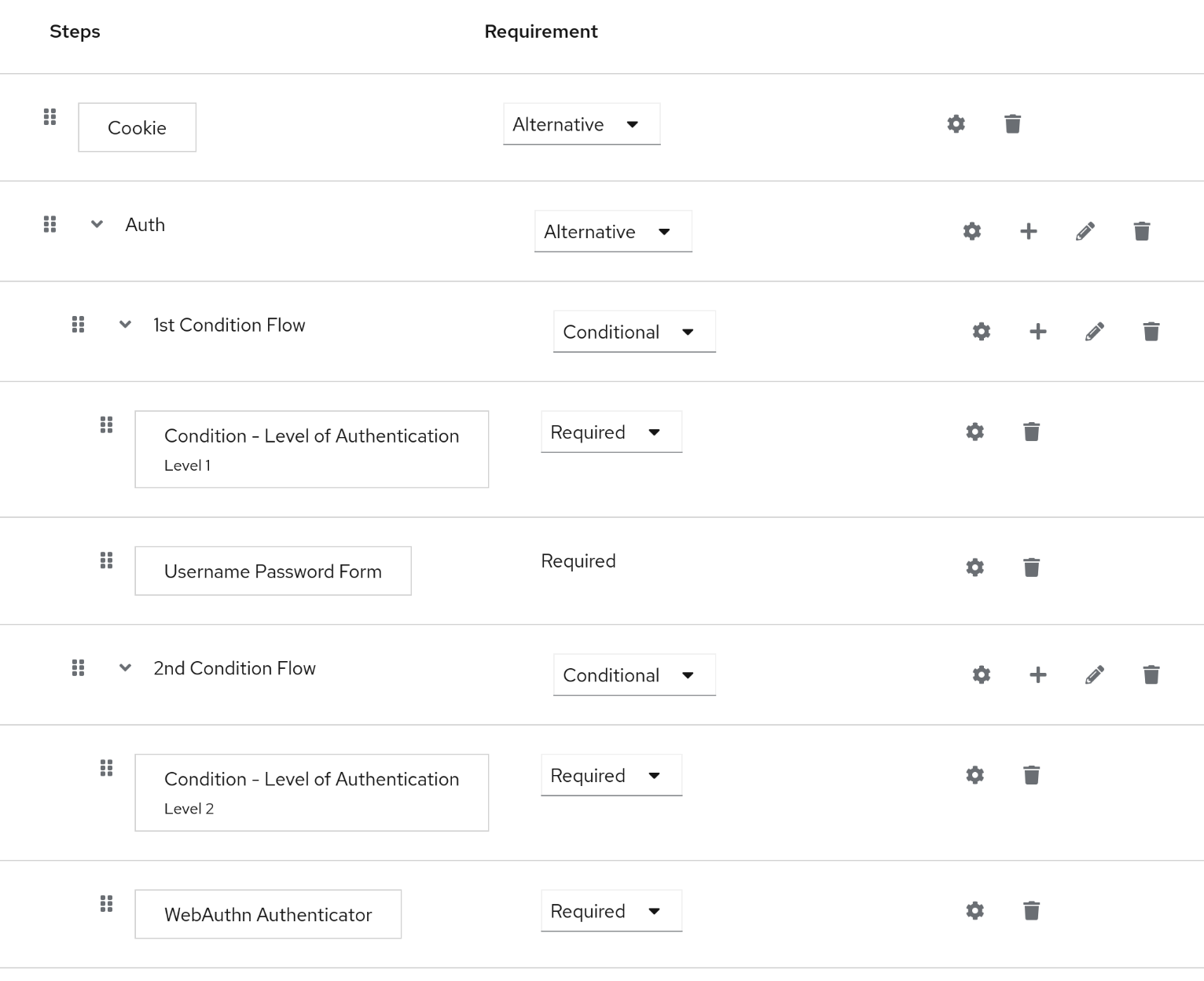
Google Login
Recently the use of third-party login systems was added in form of allowing Google Authentication to be used. Most importantly, one can not sign-up using Google Authentication, but link it to an existing Account. This allows the usage of Google Authentication with a SI-Auth account reducing the friction introduced by Authentication. Especially for Friends and Family members that are not pushing for maximum account security and struggle with MFA, this is a safe option given Google good track record of protecting from account take-overs and the device authentication integration with Android.
Using SI-Auth instead of allowing direct authentication through Google on apps directly, ensures that no accounts actually depend on Google and migrations to non-social or different social logins are easily possible.
Links
Loki
Keeping all logs centralised.
Links
Mastodon
Mastodon is the Fediverse software run in the Shivering-Isles infrastructure. It is currently running as a single-user instance.
The instance is currently deployed using a helm chart maintained as part of the GitOps repository.
SSO Enforcement
Since Mastodon itself has no configuration to enforce the presence of specific claims or roles, an oauth-proxy setup in front of the /auth/ section preventing clients from reaching the callback URL for OIDC authentication, without passing through the oauth2-proxy which can enforce the presence of a role.
While the result in a double redirect to OIDC, once by the oauth2-proxy and once by Mastodon itself, it makes sure that there is proper enforcement of the roles without requiring modification of Mastodon.
Links
Matrix
The Shivering-Isles Matrix homeserver runs Synapse and provides various Matrix Rooms to the public as well as a curated room directory.
Links
Minio
Minio provides S3-compatible object storage for all kinds of things. It’s deployed on the NAS and stores bulk storage.
Static Web Hosting
For static web hosting the Shivering-Isles Infrastructure re-uses the centralised Ingress infrastructure in combination with Minio running on the NAS.
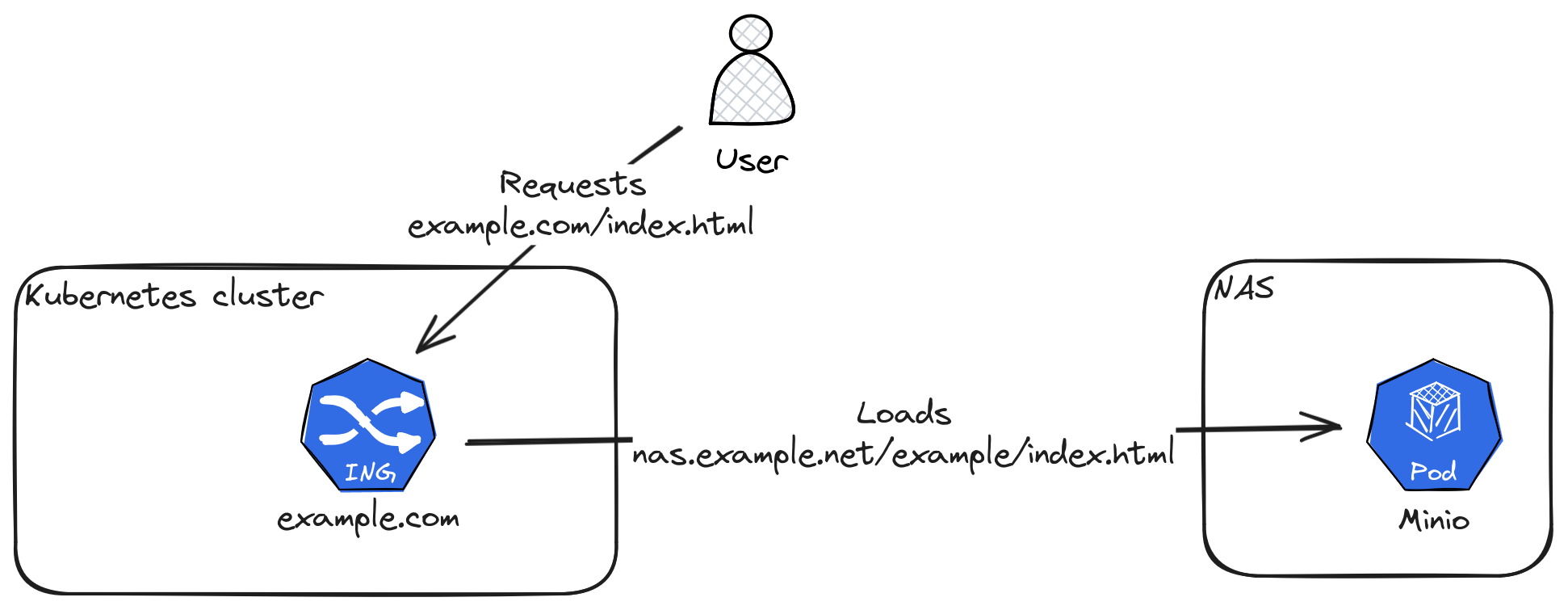
A requirement for the static webpage that links to full filenames like example.html as part of the URL.
Ingress-nginx is configured to handle the domain:
apiVersion: v1
kind: Service
metadata:
name: s3
spec:
type: ExternalName
externalName: nas.example.net
ports:
- port: 9000
name: https
protocol: TCP
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: example
annotations:
nginx.ingress.kubernetes.io/backend-protocol: HTTPS
nginx.ingress.kubernetes.io/app-root: /index.html
nginx.ingress.kubernetes.io/rewrite-target: /example/$1
spec:
rules:
- host: example.com
http:
paths:
- path: /(.*)
pathType: Prefix
backend:
service:
name: s3
port:
number: 9000
tls:
- hosts:
- example.com
secretName: example-tls
Finally a bucket example is created and the website is copied inside:
mc alias set minio https://nas.example.net:9000 example-access-key example-access-secret
mc mirror --remove --overwrite ./ minio/example
Minium GitLab integration
A minimal GitLab CI defintion to sync the current directory to a bucket would look like this:
.minio:
image:
name: docker.io/minio/mc
entrypoint: ['']
before_script:
- mc alias set minio $MINIO_ENDPOINT $MINIO_ACCESS_KEY $MINIO_ACCESS_SECRET
script:
- mc mirror --remove --overwrite ./ minio/$MINIO_BUCKET
The provided template should be extended by a job and provide the relevant environment variables.
Links
Nextcloud
Nextcloud is a self-hosted file sync and share platform providing cloud storage with clients for desktop and mobile devices.
Nice to knows
- The Nextcloud chart used here is
deprecated: truein Chart.yaml. The deployment was migrated from the deprecated upstream chart to a direct HelmRelease configuration using the Zalando Postgres Operator for the database instead of the bundled MariaDB. - Proxy body size is set to 4G to accommodate large file uploads. If clients report upload failures, this is the first place to check.
Links
Paperless
Paperless-ngx is a open-source document management system. It provides the ability to organise and manage copies of digital and physical documents and makes them searchable.
In the Shivering-Isles infrastructure it provides a secure place to store documents with strong isolation features.
Usage
Create a kustomization.yaml in your GitOps setup:
# kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: paperless
resources:
- https://git.shivering-isles.com/shivering-isles/infrastructure-gitops//apps/base/paperless?ref=main
- ingress.yaml
components:
- https://git.shivering-isles.com/shivering-isles/infrastructure-gitops//apps/base/paperless/postgres-zalando?ref=main
- https://git.shivering-isles.com/shivering-isles/infrastructure-gitops//apps/base/paperless/redis-keydb?ref=main
# optional
- https://git.shivering-isles.com/shivering-isles/infrastructure-gitops//apps/base/paperless/gotenberg?ref=main
# optional
- https://git.shivering-isles.com/shivering-isles/infrastructure-gitops//apps/base/paperless/tika?ref=main
# common labels help to identify common resources
commonLabels:
app.kubernetes.io/name: paperless
app.kubernetes.io/instance: paperless
# Config example
# secretGenerator:
# - name: paperless
# literals:
# - PAPERLESS_URL=https://paperless.example.com/
# - PAPERLESS_ADMIN_USER=paperless
# - PAPERLESS_ADMIN_PASSWORD=paperless
Add your Ingress configuration:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: paperless
annotations:
# proxy-body-size is set to 0 to remove the body limit on file uploads
nginx.ingress.kubernetes.io/proxy-body-size: "0"
labels: {}
spec:
rules:
- host: paperless.example.com
http:
paths:
- backend:
service:
name: webserver
port:
name: http
path: /
pathType: Prefix
tls:
- hosts:
- paperless.example.com
secretName: ingress-tls
And optionally use the secretGenerator from above to configure your instance to your needs.
Security
Given the sensitive nature of the documents stored in paperless, the instance is isolated by restricting access to VPN-only, adding step-up authentication to minimize access times, and isolate the network of all related containers from and to the internet.
Workflow
The majority of the workflow currently used is based on this presentation and the best-practices mentioned in the documentation.
References
Renovate
Renovate is a self-hosted dependency update bot that scans Git repositories and creates merge requests for outdated dependencies.
Links
s3dav-proxy
s3dav-proxy is a simple proxy service that translates webdav calls to minio S3 calls, providing an easy way to integrate webdav-based applications, like GrapheneOS’ Seedvault implementations with Minio.
In order to use it, one needs to specify a minio backend:
patches:
- patch: |
- op: add
path: /spec/template/spec/containers/0/args/-
value: --secure
- op: add
path: /spec/template/spec/containers/0/args/-
value: --endpoint
- op: add
path: /spec/template/spec/containers/0/args/-
value: minio.example.com:9000
target:
group: apps
version: v1
kind: 'Deployment'
name: s3dav-proxy
This can be done as part of your customization.
Links
Tekton
Tekton is an open-source framework for creating continuous integration and continuous delivery (CI/CD) systems, designed to run on Kubernetes. It provides a set of reusable components, known as “Tasks” and “Pipelines,” that enable developers to define and automate their software delivery processes. By leveraging Kubernetes-native resources, Tekton allows for scalable and flexible workflows that can integrate with various tools and services in the cloud-native ecosystem.
Uptime Kuma
Uptime Kuma is a monitoring tool that checks HTTP, TCP, Ping, DNS, and other endpoints. It provides a dashboard with status pages and notification integrations.
Nice to knows
- The liveness probe was disabled because it caused issues during migrations from v1 to v2.
- The Recreate update strategy means there will be brief downtime during updates.
Links
VersityGW
VersityGW is a high-performance S3 object storage gateway that translates S3 API requests into equivalent operations on backend storage systems. It runs as a single, stateless binary and supports POSIX filesystems, ScoutFS, Azure Blob Storage, and other S3 servers as backends.
The POSIX backend stores objects directly as files on the filesystem. An object at backups/db-2026-06-29.sql.gz in a bucket appears at the corresponding path under the root directory.
Ingress
To expose VersityGW behind the centralised Ingress infrastructure:
apiVersion: v1
kind: Service
metadata:
name: versitygw
spec:
type: ExternalName
externalName: nas.example.net
ports:
- port: 30157
name: https
protocol: TCP
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: s3gw
annotations:
nginx.ingress.kubernetes.io/backend-protocol: HTTPS
spec:
rules:
- host: s3gw.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: versitygw
port:
name: https
tls:
- hosts:
- s3gw.example.com
secretName: versitygw-tls
Usage
Interact with VersityGW using any S3-compatible client:
mc alias set versitygw https://s3gw.example.com access-key secret-key
mc ls versitygw
mc cp backup.sql versitygw/backups/
Links
Components
Overview over cluster components, their function, useful links and things that would have been nice to know beforehand.
Calico
Calico
This component provides general networking to the cluster. The overlay network is kept simple since the goal are small scale clusters. However it uses Wireguard to encrypt all traffic within the cluster.
Hint: This component also has a bootstrap component.
Nice to knows
The operator provides its own set of CRDs, examples from the docs, won’t work by default. Operator usesYou have to install the calico API server in order to use the correct CRD versions.crd.projectcalico.org/v1while calico itself usesprojectcalico.org/v3- metallb is required to be setup as host-endpoint in case you want to protect hosts with a
GlobalNetworkPolicy. - Additional network interfaces, like VPN interfaces, can confuse calico and result in routing everything over that VPN instead of the local network ports. Check the
projectcalico.org/IPv4Address-annotation.
Links
Cert-Manager
This component provides certificates to applications and internal components using lets encrypt or any other kind of CA.
Links
Error Pages
Custom HTTP error pages are served by tarampampam/error-pages using the connection theme.
Links
ExternalDNS
ExternalDNS synchronises Kubernetes Services and Ingresses with an external DNS provider, automatically managing DNS records as resources are created and removed.
Links
FluxCD
FluxCD is a GitOps controller. It synchronizes the content of a Git repository with a Kubernetes Cluster and makes sure the configurations are applied.
The main advantage over a push based approach such as a CI pipeline, is that a GitOps operator continously reconciles the state and runs on fully standardised operations. This avoids temporary and custom state in that is common in CI pipelines that might become hard to reproduce once the pipeline is gone.
Links
gVisor
gVisor is a container runtime developed by Google to isolate containers from the host OS and secure the container execution.
In order to run container in gVisor, the CRI-shim has to have gVisor configured as runtime. This can be done on Talos using the gVisor extension, or on any other host system by following the install instructions.
On hardware deployments, using the KVM platform mode, provides the best isolation by running each individual Pod as a VM on the host system, while utilising all benefits from Containers, like images, networking and storage.
References
nginx-system
This component provides ingress-nginx as ingress solution to the cluster.
Nice to knows
- You have to enabled
externalTrafficPolicyto allownginx.ingress.kubernetes.io/whitelist-source-range
Links
kata-containers
kata-containers is a container runtime that isolates container workloads using virtual machines.
Similar to gVisor it uses a separate runtime class to be selected for workload and allows gaining the benefits of VMs with the handling of containers.
References
Logging
Promtail runs as a DaemonSet across all cluster nodes, collecting system logs from journald and syslog and forwarding them to Loki for centralised storage and querying.
Links
Longhorn
This component is deployed to provide persistent storage replicated across the nodes in an easy fashion.
Current issues
- As described in issue 7183 Longhorn v1.5.3 fails to recover from certain states for share-managers. The workaround was documented upstream.. Should be resolved in 1.6.x
Nice to knows
- volume-expansion is offline expansion only. This means you have to scale down deployments to expand volumes.
- Adjusting the defaults in the helm deployment, doesn’t adjust them in production. Production is managed with
settings.longhorn.ioobjects which are basically a key-value CRD. - Longhorn requests by default 12% of your node CPUs for each instance-manager. This can easily exhaust your CPU resources in the cluster. Adjust this setting can only be done when all your volumes are detached, which implies scaling down all deployments that use volumes. (The deployment in this directory adjusted the CPU requests to 2%).
- There are some opt-out telemetry settings since version 1.6.0.
Links
MetalLB
This component provides loadbalancer capabilities within the cluster. Since physical clusters might don’t have a LB in front, no cloud provider integration and want to provide loadbalancer-type services as part of deployments, metallb provides exactly this. This installation uses the L2 capabilities since the focus are small clusters without a BGP remote.
Links
Monitoring
The monitoring is built around the kube-prometheus-stack. The standard monitoring stack in the Kubernetes space. It’s based on the prometheus-operator, that manages Prometheus and Alertmanager and integrates them with the Kubernetes API, and Grafana, which is used to provide dashboards and visualisation.
Additionally it deploys Sloth, as SLO solution. It provides an SLO CRD to allow apps to define their own SLOs which can provide lazier alerting based on error budgets.
Grafana
Grafana is a platform for monitoring and observabiltiy. It’s offered in form of a self-hostable install as well as a Cloud offering called “Grafana Cloud”, which also includes some proprietary bits.
SSO
Grafana configuration for SSO using OIDC.
Using the Grafana Helm Chart (which is also part of the kube-prometheus-stack):
grafana.ini:
users:
default_theme: system
default_language: detect
auth:
disable_login_form: true
oauth_auto_login: true
signout_redirect_url: https://keycloak.example.com/realms/my-realm/protocol/openid-connect/logout
"auth.generic_oauth":
name: OIDC-Auth
enabled: true
allow_sign_up: true
client_id: $__file{/etc/secrets/auth_generic_oauth/client_id}
client_secret: $__file{/etc/secrets/auth_generic_oauth/client_secret}
auth_url: https://keycloak.example.com/realms/my-realm/protocol/openid-connect/auth
token_url: https://keycloak.example.com/realms/my-realm/protocol/openid-connect/token
api_url: https://keycloak.example.com/realms/my-realm/protocol/openid-connect/userinfo
role_attribute_path: |
contains(roles[*], 'admin') && 'Admin' || contains(roles[*], 'editor') && 'Editor' || 'Viewer'
scopes: openid email profile roles
feature_toggles:
enable: accessTokenExpirationCheck
The various URLs can be found the well-known metadata of your OIDC provider for example: https://keycloak.example.com/realms/my-realm/.well-known/openid-configuration
In Keycloak there are 2 defined client roles called admin and editor, which are mapped to the token attribute roles in the ID token, access token and userinfo.
The upstream documentation also provides some details on how to configure Grafana with Keycloak.
Links
- prometheus-operator Docs
- kube-prometheus-stack Helm Chart
- kube-prometheus-stack Source Code
- Runbooks
- Sloth Docs
- Sloth Helm Chart
- Sloth Source Code
Node-Feature-Discovery
This component provides Node capability discovery to the cluster. It labels all nodes with various capabilities from CPU and more. Most noteworthy are System ID and version, providing useful metadata to the system-upgrades component.
Links
oauth2-proxy
The Shivering-Isles infrastructure utilises oauth2-proxy as an authentication gateway for applications that are not intended for internet exposure. Utilising the ingress-nginx feature to delegate authentication to an application before passing traffic on to the actual application, oauth2-proxy is used to ensure SSO protection for apps with limited OIDC support.
This includes apps like Paperless, that use oauth2-proxy to configure step-up authentication and ensure short lived sessions.
The oauth2-proxy installation is provided by a shared component.
Policy
Policies
Collection of ValidatingAdmissionPolicies for the Shivering-Isles infrastructure. Main goal is to prevent footguns, not enforcing better security.
The security aspects will be handled on the GitOps side of things.
PostgreSQL Operator
The Postgres operator manages PostgreSQL clusters on Kubernetes (K8s):
- The operator watches additions, updates, and deletions of PostgreSQL cluster manifests and changes the running clusters accordingly. For example, when a user submits a new manifest, the operator fetches that manifest and spawns a new Postgres cluster along with all necessary entities such as K8s StatefulSets and Postgres roles. See this Postgres cluster manifest for settings that a manifest may contain.
- The operator also watches updates to its own configuration and alters running Postgres clusters if necessary. For instance, if the Docker image in a pod is changed, the operator carries out the rolling update, which means it re-spawns pods of each managed StatefulSet one-by-one with the new Docker image.
- Finally, the operator periodically synchronizes the actual state of each Postgres cluster with the desired state defined in the cluster’s manifest.
- The operator aims to be hands free as configuration works only via manifests. This enables easy integration in automated deploy pipelines with no access to K8s directly.
— postgres-operator.readthedocs.io
In the Shivering-Isles Infrastructure the Zalando Postgres Operator is used to manage highly available database clusters for all applciations. Takes away a lot of the common pain points for applications, such as postgresql updates, and standardises backups using point-in-time recovery as well as monitoring.
Tools
For postgres database management the SI-Infra repository contains multiple tools.
psql- is a simple wrapper for psql inside one of the postgresql clusterpatronictl- allows easy access to patronictl of a cluster and manage everything from failovers to simple member statuszpg- provides a simplied interface for common tasks with multiple steps, such as recreating a member of a postgresql cluster
Backups
Zalando Postgres Operator provides a two built-in mechanisms for backups:
In both cases the target is an S3 compatible endpoint, but they don’t have to be the same.
While these can be different per cluster, for simplicity, in the SI-Infra the credentails are globally managed.
Restore
Automatic restore
If PostgreSQL-Pods are missing the content volumes at any point, they’ll automatically grab the latest available backup, restore it and then stream the remaining delta from currently active cluster members if possible.
This mechanism is quite battle-tested in SI-Infra and the default way of solving single-member issues in postgresql clusters.
Manual restore base backup
If a cluster object was deleted a restore can be done using the old cluster uid:
apiVersion: "acid.zalan.do/v1"
kind: postgresql
metadata:
name: example-postgres
spec:
clone:
uid: "<original-uid>"
cluster: "example-postgres"
The original uid can easily be found in S3 as they are part of the path to the backups.
Manual restore logical backup
If logical backups have been enabled for the cluster, they are available as simple pg_dump files in S3.
To manually restore these, download the dump and run pg_restore.
Links
System-Upgrades
This component does the majority of host management. It utilises the system-upgrades-controller from Rancher to do this. It deploys longhorn volumes on the host-side, updates kubelet config, installs software and runs weekly system upgrades and takes care of reboot requirements. In order to make all of this safe, the operator takes care of cordoning, draining and uncordoning nodes before doing some of these operations.
It also provides a calver-server, that does nothing more than providing either weekly or monthly redirects in the CalVer format. This is used as channel provider for the weekly system upgrades.
Nice to knows
- Plans only run once unless their version changes or the secret that is assigned to them changes. However there is a
channel:statement in the plan, that allows to provide a URL that redirects to a version. The controller will take the last component of the URL that the location-header of this redirect points to and uses that as version.
Links
Traefik
Traefik replaces ingress-nginx as the cluster’s ingress controller. ingress-nginx was retired and reached end-of-life in March 2026.
Why Traefik?
Traefik is the most established drop-in replacement that supports the kubernetesIngressNGINX provider, meaning existing Ingress resources continue working without changes. As a secondary benefit, Traefik handles proxy-protocol natively per entrypoint, which removes the in-cluster HAProxy sidecar that was needed to bridge the gap between LAN traffic (no proxy-protocol) and VPS traffic (with proxy-protocol).
Intranet / Internet split
The two-instance architecture was carried over from ingress-nginx and serves two purposes:
Security isolation: The internet-facing instance is exposed to untrusted traffic from the wider internet. If it were ever compromised, the intranet instance and its connected backends would remain unaffected: an attacker would still need to find a separate path into internal services. The split also limits the blast radius of misconfigurations: a mistake in the external HTTPS redirect or rate limiting won’t affect internal traffic.
Different traffic profiles: Internet traffic arrives via the VPS with proxy-protocol enabled and must be redirected from HTTP to HTTPS. LAN traffic arrives directly via iptables without proxy-protocol and should not require HTTPS termination for local clients. Each instance can be tuned for its own load profile, resource limits, and security policies without impacting the other.
The two instances use distinct ingress class names so Ingress resources explicitly opt into one or the other:
traefik-intranet:k8s.io/ingress-nginx-intranetfor LAN traffictraefik-internet:k8s.io/ingress-nginx-internetfor traffic from the VPS
Both read from the same shared base configuration and are deployed via separate Flux HelmReleases with per-instance value overrides.
Error pages
Custom HTTP error pages are served from the errorpages-system namespace, covering 4xx and 5xx status codes. The tarampampam/error-pages project provides the content, using the connection theme: it’s clean and gives end users a clear indication of where to look when something goes wrong.
Links
Valkey
The Valkey Operator manages Valkey clusters on Kubernetes. Valkey is the open-source successor to Redis, providing an in-memory data store for caching, session storage, and message brokering.
Links
Velero
Velero is an open source tool to safely backup and restore, perform disaster recovery, and migrate Kubernetes cluster resources and persistent volumes.
— velero.io
This module deploys Velero with CSI Snapshot Data Mover support to backup Kubernetes resources and persistent volumes to an S3-compatible backend. Volume snapshots are taken via Longhorn CSI and moved to the S3 bucket, enabling off-site disaster recovery and cluster migration.
The base layer configures the shared Velero settings (CSI feature gate, data mover, schedules, monitoring alerts). Cluster-specific overrides supply the S3 endpoint, credentials, the AWS plugin init container, and the CSI volume snapshot class.
Prerequisites
- The
kubernetes-backupsbucket must exist in the S3-compatible backend. - Credentials for the S3 backup location must be provided via the cluster-specific override (
release-override.yamlor avelero-credentialsSecret). - The
velero-plugin-for-awsinit container must be configured in the cluster-specific override to enable S3-compatible storage. - CSI snapshot support must be available (
external-snapshotterinkube-system). - A
VolumeSnapshotClassannotated withvelero.io/csi-volumesnapshot-class: "true"must exist. - Postgres PVCs (labeled
application: spilo) are excluded from volume backup via a VolumePolicy rather than by excluding the resources entirely. This preserves the PVC metadata in the backup while skipping the volume data.
Cluster override
The following values must be set in the cluster-specific release-override.yaml:
initContainers:
- name: velero-plugin-for-aws
image: velero/velero-plugin-for-aws:v1.14.0
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /target
name: plugins
configuration:
backupStorageLocation:
- name: default
provider: aws
bucket: kubernetes-backups
default: true
config:
region: us-east-1
s3ForcePathStyle: "true"
s3Url: https://minio.example.com:9000
volumeSnapshotLocation:
- name: default
provider: csi
Credentials can be provided inline (useSecret + secretContents) or via a separate velero-credentials Secret.
Examples
Ad-hoc backup for a single namespace
apiVersion: velero.io/v1
kind: Backup
metadata:
generateName: example-backup-
namespace: velero-system
spec:
includedNamespaces:
- example
storageLocation: default
volumeSnapshotLocations:
- default
snapshotMoveData: true
resourcePolicy:
kind: ConfigMap
name: resource-policies
ttl: 72h
Restore a namespace from backup
apiVersion: velero.io/v1
kind: Restore
metadata:
generateName: example-restore-
namespace: velero-system
spec:
backupName: example-backup-<random-suffix>
includedNamespaces:
- example
restoreVolumes: true
resourceModifier:
kind: ConfigMap
name: resource-modifiers
Links
VPA
The Kubernetes Vertical Pod Autoscaler automatically adjusts CPU and memory requests for pods based on historical and real-time usage, helping to right-size workloads without manual intervention.
Links
Helm Charts
Various helm charts maintained as part of the Shivering-Isles GitOps monorepo.
hedgedoc
A platform to write and share markdown.
(Be aware: This is currently a PoC and not necessarily fit for all use-cases. It is mainly built for use with external PostgresQL databases.)
Homepage: https://hedgedoc.org
Maintainers
| Name | Url | |
|---|---|---|
| Sheogorath | https://shivering-isles.com |
Source Code
- https://github.com/hedgedoc/hedgedoc/tree/master
- https://git.shivering-isles.com/shivering-isles/infrastructure-gitops/-/tree/main/charts/hedgedoc
Requirements
| Repository | Name | Version |
|---|---|---|
| oci://docker.io/cloudpirates | postgresql(postgres) | 0.19.6 |
Values
| Key | Type | Default | Description |
|---|---|---|---|
| affinity | object | {} | |
| config.allowFreeUrl | bool | false | |
| config.defaultPermission | string | "freely" | |
| config.domain | string | nil | |
| config.email | bool | false | |
| config.github.clientId | string | nil | |
| config.github.clientSecret | string | nil | |
| config.minio.accessKey | string | nil | |
| config.minio.endpoint | string | nil | |
| config.minio.port | int | 443 | |
| config.minio.secretKey | string | nil | |
| config.minio.secure | bool | true | |
| config.oauth.accessRole | string | nil | |
| config.oauth.authorisationUrl | string | nil | |
| config.oauth.clientId | string | nil | |
| config.oauth.clientSecret | string | nil | |
| config.oauth.providerName | string | nil | |
| config.oauth.roleClaim | string | nil | |
| config.oauth.scope | string | "openid email profile" | |
| config.oauth.tokenUrl | string | nil | |
| config.oauth.userProfileDisplayName | string | "name" | |
| config.oauth.userProfileEmailAttr | string | "email" | |
| config.oauth.userProfileUrl | string | nil | |
| config.oauth.userProfileUsername | string | "preferred_username" | |
| config.protocolUseSsl | bool | true | |
| config.s3bucket | string | "hedgedoc" | |
| config.session.lifeTime | int | 36000000 | |
| config.session.secret | string | nil | |
| config.urlAddPort | bool | false | |
| config.useCdn | bool | false | |
| fullnameOverride | string | "" | |
| image.pullPolicy | string | "IfNotPresent" | configures image pull policy for hedgedoc deployment |
| image.repository | string | "quay.io/hedgedoc/hedgedoc" | |
| image.tag | string | "" | Overrides the image tag whose default is the chart appVersion. |
| imagePullSecrets | list | [] | |
| ingress.annotations | object | {} | |
| ingress.className | string | "" | |
| ingress.enabled | bool | false | |
| ingress.hosts[0].host | string | "hedgedoc.example.com" | |
| ingress.hosts[0].paths[0].path | string | "/" | |
| ingress.hosts[0].paths[0].pathType | string | "ImplementationSpecific" | |
| ingress.tls | list | [] | |
| nameOverride | string | "" | |
| nodeSelector | object | {} | |
| podAnnotations | object | {} | |
| podSecurityContext.fsGroup | int | 10000 | |
| podSecurityContext.seccompProfile.type | string | "RuntimeDefault" | |
| postgresql.auth.database | string | "hedgedoc" | |
| postgresql.auth.existingSecret | string | "" | |
| postgresql.auth.password | string | "" | |
| postgresql.auth.username | string | "hedgedoc" | |
| postgresql.enabled | bool | true | |
| postgresql.tls.enabled | bool | false | |
| resources | object | {} | |
| runtimeClassName | string | nil | |
| securityContext.allowPrivilegeEscalation | bool | false | |
| securityContext.capabilities.drop[0] | string | "ALL" | |
| securityContext.readOnlyRootFilesystem | bool | true | |
| securityContext.runAsNonRoot | bool | true | |
| securityContext.runAsUser | int | 10000 | |
| service.port | int | 80 | |
| service.type | string | "ClusterIP" | |
| serviceAccount.annotations | object | {} | Annotations to add to the service account |
| serviceAccount.create | bool | true | Specifies whether a service account should be created |
| serviceAccount.name | string | "" | The name of the service account to use. If not set and create is true, a name is generated using the fullname template |
| tolerations | list | [] |
keycloak
A Helm chart for Keycloak on Kubernetes
Homepage: https://www.keycloak.org/
Maintainers
| Name | Url | |
|---|---|---|
| Sheogorath | https://shivering-isles.com |
Source Code
- https://git.shivering-isles.com/shivering-isles/infrastructure-gitops
- https://github.com/keycloak/keycloak
Requirements
Kubernetes: >=1.25
Values
| Key | Type | Default | Description |
|---|---|---|---|
| adminIngress | object | {"annotations":{},"className":"","enabled":false,"hosts":[{"host":"chart-example.local","paths":[{"path":"/js/","pathType":"ImplementationSpecific"},{"path":"/realms/","pathType":"ImplementationSpecific"},{"path":"/resources/","pathType":"ImplementationSpecific"},{"path":"/robots.txt","pathType":"ImplementationSpecific"},{"path":"/admin/","pathType":"ImplementationSpecific"}]}],"tls":[]} | Optional separate ingress endpoint when keycloak.adminHostname is used |
| affinity | object | {} | |
| autoscaling.enabled | bool | false | |
| autoscaling.maxReplicas | int | 100 | |
| autoscaling.minReplicas | int | 1 | |
| autoscaling.targetCPUUtilizationPercentage | int | 80 | |
| fullnameOverride | string | "" | |
| image.pullPolicy | string | "IfNotPresent" | pull policy used for the keycloak container |
| image.repository | string | "quay.io/keycloak/keycloak" | Keycloak image to be used |
| image.tag | string | "" | Overrides the image tag whose default is the chart appVersion. |
| imagePullSecrets | list | [] | |
| ingress.annotations | object | {} | |
| ingress.className | string | "" | |
| ingress.enabled | bool | false | |
| ingress.hosts[0].host | string | "chart-example.local" | |
| ingress.hosts[0].paths[0].path | string | "/js/" | |
| ingress.hosts[0].paths[0].pathType | string | "ImplementationSpecific" | |
| ingress.hosts[0].paths[1].path | string | "/realms/" | |
| ingress.hosts[0].paths[1].pathType | string | "ImplementationSpecific" | |
| ingress.hosts[0].paths[2].path | string | "/resources/" | |
| ingress.hosts[0].paths[2].pathType | string | "ImplementationSpecific" | |
| ingress.hosts[0].paths[3].path | string | "/robots.txt" | |
| ingress.hosts[0].paths[3].pathType | string | "ImplementationSpecific" | |
| ingress.tls | list | [] | |
| keycloak.adminHostname | string | nil | Optional Admin Hostname, see https://www.keycloak.org/server/hostname#_administration_console |
| keycloak.database.password | string | nil | password of the database user |
| keycloak.database.type | string | "postgres" | Type of the database, see db at https://www.keycloak.org/server/db#_configuring_a_database |
| keycloak.database.url | string | nil | database URL, see db-url at https://www.keycloak.org/server/db#_configuring_a_database jdbc:postgresql://localhost/keycloak |
| keycloak.database.username | string | nil | username of the database user |
| keycloak.features | list | [] | list of features that should be enabled on the keycloak instance. See features at https://www.keycloak.org/server/containers#_relevant_options |
| keycloak.hostname | string | "keycloak.example.com" | Hostname used for the keycloak installation |
| metrics.enabled | bool | false | |
| metrics.interval | string | nil | |
| metrics.scrapeTimeout | string | nil | |
| nameOverride | string | "" | |
| networkPolicy.create | bool | false | Creates a network policy for inifispan communication, does not take care of database or ingress communication |
| nodeSelector | object | {} | |
| podAnnotations | object | {} | |
| podSecurityContext.runAsNonRoot | bool | true | |
| podSecurityContext.seccompProfile.type | string | "RuntimeDefault" | |
| replicaCount | int | 1 | |
| resources.limits.cpu | string | "2" | |
| resources.limits.memory | string | "2Gi" | |
| resources.requests.cpu | string | "200m" | |
| resources.requests.memory | string | "1Gi" | |
| securityContext.allowPrivilegeEscalation | bool | false | |
| securityContext.capabilities.drop[0] | string | "ALL" | |
| service.type | string | "ClusterIP" | |
| serviceAccount.annotations | object | {} | Annotations to add to the service account |
| serviceAccount.create | bool | true | Specifies whether a service account should be created |
| serviceAccount.name | string | "" | The name of the service account to use. If not set and create is true, a name is generated using the fullname template |
| tolerations | list | [] | |
| topologySpreadConstraints | list | [] |
mastodon
Mastodon is a free, open-source social network server based on ActivityPub.
This unofficical Helm chart is maintained to the best of knowledge, with the limitation that migration steps for dependencies are not documented or tested. This is mainly due to the fact that postgresql and redis in the SI-Production are ran by operators instead of helm dependencies.
Homepage: https://joinmastodon.org
Source Code
- https://github.com/mastodon/mastodon
- https://git.shivering-isles.com/shivering-isles/infrastructure-gitops/-/tree/main/charts/mastodon
Requirements
Kubernetes: >= 1.23
| Repository | Name | Version |
|---|---|---|
| https://valkey.io/valkey-helm/ | valkey | 0.9.4 |
| oci://docker.io/cloudpirates | postgresql(postgres) | 0.19.6 |
Values
| Key | Type | Default | Description |
|---|---|---|---|
| affinity | object | {} | Affinity for all pods unless overwritten |
| externalAuth.cas.enabled | bool | false | |
| externalAuth.ldap.enabled | bool | false | |
| externalAuth.oauth_global.omniauth_only | bool | false | Automatically redirect to OIDC, CAS or SAML, and don’t use local account authentication when clicking on Sign-In |
| externalAuth.oidc.enabled | bool | false | OpenID Connect support is proposed in PR #16221 and awaiting merge. |
| externalAuth.pam.enabled | bool | false | |
| externalAuth.saml.enabled | bool | false | |
| image.pullPolicy | string | "IfNotPresent" | |
| image.repository | string | "ghcr.io/mastodon/mastodon" | |
| image.tag | string | "" | |
| ingress.annotations | string | nil | |
| ingress.enabled | bool | true | |
| ingress.hosts[0].host | string | "mastodon.local" | |
| ingress.hosts[0].paths[0].path | string | "/" | |
| ingress.ingressClassName | string | nil | you can specify the ingressClassName if it differs from the default |
| ingress.tls[0].hosts[0] | string | "mastodon.local" | |
| ingress.tls[0].secretName | string | "mastodon-tls" | |
| jobAnnotations | object | {} | The annotations set with jobAnnotations will be added to all job pods. |
| mastodon.authorizedFetch | bool | false | Enables “Secure Mode” for more details see: https://docs.joinmastodon.org/admin/config/#authorized_fetch |
| mastodon.createAdmin | object | {} | create an initial administrator user; the password is autogenerated and will have to be reset |
| mastodon.cron.removeMedia | object | {} | run tootctl media remove every week |
| mastodon.disallowUnauthenticatedAPIAccess | bool | false | Restores previous behaviour of “Secure Mode” |
| mastodon.local_domain | string | "mastodon.local" | |
| mastodon.locale | string | "en" | available locales: https://github.com/mastodon/mastodon/blob/main/config/application.rb#L71 |
| mastodon.metrics | object | {} | |
| mastodon.persistence.assets.accessMode | string | "ReadWriteOnce" | ReadWriteOnce is more widely supported than ReadWriteMany, but limits scalability, since it requires the Rails and Sidekiq pods to run on the same node. |
| mastodon.persistence.assets.resources.requests.storage | string | "10Gi" | |
| mastodon.persistence.system.accessMode | string | "ReadWriteOnce" | |
| mastodon.persistence.system.resources.requests.storage | string | "100Gi" | |
| mastodon.preparedStatements | bool | true | Sets the PREPARED_STATEMENTS environment variable: https://docs.joinmastodon.org/admin/config/#prepared_statements |
| mastodon.redis | object | {"host":null,"passwordKey":null,"port":null,"secretName":null,"sentinel":{"master":null,"passwordKey":null,"secretName":null,"sentinels":null,"usernameKey":null},"url":null,"usernameKey":null} | If valkey is not enabled, this section is used to connect to an external Redis/Valkey |
| mastodon.redis.secretName | string | nil | reference to a secret storying username, password or both for redis/valkey auth |
| mastodon.redis.sentinel.master | string | nil | The name of the Redis Sentinel master to connect to. |
| mastodon.redis.sentinel.secretName | string | nil | reference to a secret storying username, password or both for sentinel auth |
| mastodon.redis.sentinel.sentinels | string | nil | A comma-delimited list of Redis Sentinel instance HOST:PORTs. The port number is optional, if omitted it will use the value given in REDIS_SENTINEL_PORT or the default of 26379. |
| mastodon.redis.url | string | nil | alternative to host + port to provide a redis URLs. If you need to use TLS to connect to your Redis server, you must use REDIS_URL with the protocol scheme rediss:// |
| mastodon.s3.access_key | string | "" | |
| mastodon.s3.access_secret | string | "" | |
| mastodon.s3.alias_host | string | "" | If you have a caching proxy, enter its base URL here. |
| mastodon.s3.bucket | string | "" | |
| mastodon.s3.enabled | bool | false | |
| mastodon.s3.endpoint | string | "" | |
| mastodon.s3.existingSecret | string | "" | you can also specify the name of an existing Secret with keys AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY |
| mastodon.s3.hostname | string | "" | |
| mastodon.s3.region | string | "" | |
| mastodon.secrets.activeRecordEncryption | object | {"deterministicKey":"","keyDerivationSalt":"","primaryKey":""} | Generate these using podman run -it ghcr.io/mastodon/mastodon:v4.3.1 bin/rails db:encryption:init or kubectl run -it –image=ghcr.io/mastodon/mastodon:v4.3.1 mastodon-encryption-init – bin/rails db:encryption:init |
| mastodon.secrets.existingSecret | string | "" | you can also specify the name of an existing Secret with keys SECRET_KEY_BASE and OTP_SECRET and VAPID_PRIVATE_KEY and VAPID_PUBLIC_KEY |
| mastodon.secrets.otp_secret | string | "" | |
| mastodon.secrets.secret_key_base | string | "" | |
| mastodon.secrets.vapid.private_key | string | "" | |
| mastodon.secrets.vapid.public_key | string | "" | |
| mastodon.sidekiq.affinity | object | {} | Affinity for all Sidekiq Deployments unless overwritten, overwrites .Values.affinity |
| mastodon.sidekiq.podSecurityContext | object | {} | Pod security context for all Sidekiq Pods, overwrites .Values.podSecurityContext |
| mastodon.sidekiq.redis.host | string | nil | redis host explicitly for sidekiq usage |
| mastodon.sidekiq.redis.passwordKey | string | nil | |
| mastodon.sidekiq.redis.port | string | nil | redis port explicitly for sidekiq usage |
| mastodon.sidekiq.redis.secretName | string | nil | reference to a secret storying username, password or both for redis/valkey auth |
| mastodon.sidekiq.redis.url | string | nil | redis url explicitly for sidekiq usage |
| mastodon.sidekiq.redis.usernameKey | string | nil | |
| mastodon.sidekiq.resources | object | {} | Resources for all Sidekiq Deployments unless overwritten |
| mastodon.sidekiq.securityContext | Sidekiq Container | {"readOnlyRootFilesystem":true} | Security Context for all Pods, overwrites .Values.securityContext |
| mastodon.sidekiq.temporaryVolumeTemplate | object | {"emptyDir":{"medium":"Memory"}} | temporary volume template required for read-only root filesystem |
| mastodon.sidekiq.workers[0].affinity | object | {} | Affinity for this specific deployment, overwrites .Values.affinity and .Values.mastodon.sidekiq.affinity |
| mastodon.sidekiq.workers[0].concurrency | int | 25 | Number of threads / parallel sidekiq jobs that are executed per Pod |
| mastodon.sidekiq.workers[0].name | string | "all-queues" | |
| mastodon.sidekiq.workers[0].queues | list | ["default,8","push,6","ingress,4","mailers,2","fasp,2","pull,1","scheduler,1"] | Sidekiq queues for Mastodon that are handled by this worker. See https://docs.joinmastodon.org/admin/scaling/#concurrency See https://github.com/mperham/sidekiq/wiki/Advanced-Options#queues for how to weight queues as argument |
| mastodon.sidekiq.workers[0].replicas | int | 1 | Number of Pod replicas deployed by the Deployment |
| mastodon.sidekiq.workers[0].resources | object | {} | Resources for this specific deployment to allow optimised scaling, overwrites .Values.mastodon.sidekiq.resources |
| mastodon.singleUserMode | bool | false | If set to true, the frontpage of your Mastodon server will always redirect to the first profile in the database and registrations will be disabled. |
| mastodon.smtp.auth_method | string | "plain" | |
| mastodon.smtp.ca_file | string | "/etc/ssl/certs/ca-certificates.crt" | |
| mastodon.smtp.delivery_method | string | "smtp" | |
| mastodon.smtp.domain | string | nil | |
| mastodon.smtp.enable_starttls | string | "auto" | |
| mastodon.smtp.existingSecret | string | nil | you can also specify the name of an existing Secret with the keys login and password |
| mastodon.smtp.from_address | string | "notifications@example.com" | |
| mastodon.smtp.login | string | nil | |
| mastodon.smtp.openssl_verify_mode | string | "peer" | |
| mastodon.smtp.password | string | nil | |
| mastodon.smtp.port | int | 587 | |
| mastodon.smtp.reply_to | string | nil | |
| mastodon.smtp.server | string | "smtp.mailgun.org" | |
| mastodon.smtp.tls | bool | false | |
| mastodon.streaming.affinity | object | {} | Affinity for Streaming Pods, overwrites .Values.affinity |
| mastodon.streaming.base_url | string | nil | The base url for streaming can be set if the streaming API is deployed to a different domain/subdomain. |
| mastodon.streaming.image.pullPolicy | string | "IfNotPresent" | |
| mastodon.streaming.image.repository | string | "ghcr.io/mastodon/mastodon-streaming" | |
| mastodon.streaming.image.tag | string | "" | |
| mastodon.streaming.podSecurityContext | object | {} | Pod Security Context for Streaming Pods, overwrites .Values.podSecurityContext |
| mastodon.streaming.port | int | 4000 | |
| mastodon.streaming.replicas | int | 1 | Number of Streaming Pods running |
| mastodon.streaming.resources | Streaming Container | {} | Resources for Streaming Pods, overwrites .Values.resources |
| mastodon.streaming.securityContext | Streaming Container | {"readOnlyRootFilesystem":true} | Security Context for Streaming Pods, overwrites .Values.securityContext |
| mastodon.streaming.workers | int | 1 | this should be set manually since os.cpus() returns the number of CPUs on the node running the pod, which is unrelated to the resources allocated to the pod by k8s |
| mastodon.web.affinity | object | {} | Affinity for Web Pods, overwrites .Values.affinity |
| mastodon.web.podSecurityContext | object | {} | Pod Security Context for Web Pods, overwrites .Values.podSecurityContext |
| mastodon.web.port | int | 3000 | |
| mastodon.web.replicas | int | 1 | Number of Web Pods running |
| mastodon.web.resources | Web Container | {} | Resources for Web Pods, overwrites .Values.resources |
| mastodon.web.securityContext | Web Container | {"readOnlyRootFilesystem":true} | Security Context for Web Pods, overwrites .Values.securityContext |
| mastodon.web.temporaryVolumeTemplate | object | {"emptyDir":{"medium":"Memory"}} | temporary volume template required for read-only root filesystem |
| mastodon.web_domain | string | nil | Use of WEB_DOMAIN requires careful consideration: https://docs.joinmastodon.org/admin/config/#federation You must redirect the path LOCAL_DOMAIN/.well-known/ to WEB_DOMAIN/.well-known/ as described Example: mastodon.example.com |
| podAnnotations | object | {} | Kubernetes manages pods for jobs and pods for deployments differently, so you might need to apply different annotations to the two different sets of pods. The annotations set with podAnnotations will be added to all deployment-managed pods. |
| podSecurityContext | object | {"fsGroup":991,"runAsGroup":991,"runAsNonRoot":true,"runAsUser":991,"seccompProfile":{"type":"RuntimeDefault"}} | base securityContext on Pod-Level. Can be overwritten but more specific contexts. Used to match the Upstream UID/GID |
| postgresql.auth.database | string | "mastodon_production" | |
| postgresql.auth.existingSecret | string | "" | |
| postgresql.auth.password | string | "" | |
| postgresql.auth.username | string | "mastodon" | |
| postgresql.enabled | bool | true | disable if you want to use an existing db; in which case the values below must match those of that external postgres instance |
| resources | object | {} | Default resources for all Deployments and jobs unless overwritten |
| runtimeClassName | string | nil | RuntimeClass for all deployments |
| securityContext | object | {"allowPrivilegeEscalation":false,"capabilities":{"drop":["ALL"]}} | securityContext on Container-Level. Can be overwritten but more specific contexts. |
| serviceAccount.annotations | object | {} | Annotations to add to the service account |
| serviceAccount.create | bool | true | Specifies whether a service account should be created |
| serviceAccount.name | string | "" | The name of the service account to use. If not set and create is true, a name is generated using the fullname template |
| valkey.auth.enabled | bool | false | not supported |
| valkey.datastore.enabled | bool | true | |
| valkey.datastore.persistentVolumeClaimName | string | "valkey-data" | |
| valkey.datastore.requestedSize | string | "5Gi" | |
| valkey.enabled | bool | true | disable if you want to use an externally managed valkey or redis instance. It’s recommended for production to use an externally managed valkey instance. (When using externally managed redis/valkey use mastodon.redis config section) |
| valkey.metrics.enabled | bool | false | enable metrics exporter sidecar |
| valkey.metrics.prometheusRule.enabled | bool | false | Enable Prometheus rules for alerts |
| valkey.metrics.serviceMonitor.enabled | bool | false | Enable service Monitor to collect metrics |
mok
Mail on Kubernetes (MoK) is a project to deploy a functional mailserver that runs without a database server on Kubernetes, taking advantage of configmaps and secret.
Maintainers
| Name | Url | |
|---|---|---|
| Sheogorath | https://shivering-isles.com |
Source Code
Values
| Key | Type | Default | Description |
|---|---|---|---|
| deniedSenders | list | [] | list of rejected email addresses or domains. See values.yaml for Details |
| domains | object | {} | list of configured domains and users. See values.yaml for details. |
| dovecot.affinity | object | {} | |
| dovecot.image.pullPolicy | string | "IfNotPresent" | |
| dovecot.image.repository | string | "quay.io/shivering-isles/dovecot" | dovecot container image |
| dovecot.image.tag | string | "2.3.21" | Overrides the image tag whose default is “latest” |
| dovecot.imagePullSecrets | list | [] | pull secret to access the afore defined image |
| dovecot.nodeSelector | object | {} | |
| dovecot.podAnnotations | object | {} | |
| dovecot.podSecurityContext | object | {} | |
| dovecot.replicaCount | int | 1 | Number of Dovecot pods. Important: With the current configuration, it’s not recommended to scale beyond 1 |
| dovecot.resources.limits.cpu | string | "500m" | |
| dovecot.resources.limits.memory | string | "512Mi" | |
| dovecot.resources.requests.cpu | string | "100m" | |
| dovecot.resources.requests.memory | string | "128Mi" | |
| dovecot.securityContext.allowPrivilegeEscalation | bool | false | |
| dovecot.securityContext.capabilities.add[0] | string | "SYS_CHROOT" | required to setup chroot for dovecot https://wiki.dovecot.org/HowTo/Rootless |
| dovecot.securityContext.capabilities.add[1] | string | "CHOWN" | required to set up file structure |
| dovecot.securityContext.capabilities.add[2] | string | "NET_BIND_SERVICE" | required to bind privileged ports in the container, such as 993, 143, 24, etc. |
| dovecot.securityContext.capabilities.add[3] | string | "SETUID" | required to drop privileges with dovecot process |
| dovecot.securityContext.capabilities.add[4] | string | "SETGID" | required to drop privileges with dovecot process |
| dovecot.securityContext.capabilities.add[5] | string | "FOWNER" | required to create spool directories |
| dovecot.securityContext.capabilities.add[6] | string | "KILL" | required by management process to keep subprocesses in check |
| dovecot.securityContext.capabilities.drop[0] | string | "ALL" | required to drop privileges by default |
| dovecot.securityContext.runAsNonRoot | bool | false | |
| dovecot.service.internal.type | string | "ClusterIP" | type of the public endpoint for lmtp, metrics, authentication |
| dovecot.service.public.type | string | "LoadBalancer" | type of the public endpoint for pop3, imap, and sieve Note: It’s configured to share the IP with postfix in case of metallb |
| dovecot.tls.secretName | string | "nil" | secret holding the TLS keys for dovecot. Required |
| dovecot.tolerations | list | [] | |
| dovecot.volumes.vmail.accessModes | list | ["ReadWriteMany"] | Volume access mode, using ReadWriteMany in order to prepare setup with dovcecot director |
| dovecot.volumes.vmail.resources.requests.storage | string | "5Gi" | |
| dovecot.volumes.vmail.volumeMode | string | "Filesystem" | |
| fullnameOverride | string | "" | |
| nameOverride | string | "" | |
| networkPolicy.create | bool | true | Create NetworkPolicies to access the mailserver from outside |
| postfix.affinity | object | {} | |
| postfix.hostname | string | nil | explicitly set postfix hostname |
| postfix.image.pullPolicy | string | "IfNotPresent" | |
| postfix.image.repository | string | "quay.io/shivering-isles/postfix" | postfix container image |
| postfix.image.tag | string | "3.11.5" | Overrides the image tag whose default is “latest” |
| postfix.imagePullSecrets | list | [] | |
| postfix.nodeSelector | object | {} | |
| postfix.podAnnotations | object | {} | |
| postfix.podDisruptionBudget.enabled | bool | true | Enable PodDisruptionBudget if replicaCount is set to > 2 |
| postfix.podSecurityContext | object | {} | |
| postfix.postscreen.cidr | string | "127.0.0.1/32" | CIDR that is allowed to use Proxy protocol on port 10025 |
| postfix.postscreen.enabled | bool | false | Enable proxy protocol support |
| postfix.replicaCount | int | 1 | Number of postfix pods. |
| postfix.resources.limits.cpu | string | "500m" | |
| postfix.resources.limits.memory | string | "512Mi" | |
| postfix.resources.requests.cpu | string | "100m" | |
| postfix.resources.requests.memory | string | "128Mi" | |
| postfix.securityContext.allowPrivilegeEscalation | bool | false | prevent any process in the container to regain capabilities once dropped |
| postfix.securityContext.capabilities.add[0] | string | "SYS_CHROOT" | required to setup chroot with postfix |
| postfix.securityContext.capabilities.add[1] | string | "CHOWN" | required to adjust ownership of files using supervisord |
| postfix.securityContext.capabilities.add[2] | string | "NET_BIND_SERVICE" | required to bind privileged ports like 25, 465, 587 |
| postfix.securityContext.capabilities.add[3] | string | "SETUID" | required to change user id as supervisord as well as postfix |
| postfix.securityContext.capabilities.add[4] | string | "SETGID" | required to change group id as supervisord as well as postfix |
| postfix.securityContext.capabilities.add[5] | string | "FOWNER" | required to set up the chroot directory on startup |
| postfix.securityContext.capabilities.add[6] | string | "DAC_OVERRIDE" | required to setup TLS and alike |
| postfix.securityContext.capabilities.drop[0] | string | "ALL" | getting rid of all capabilities since we already have too many |
| postfix.securityContext.runAsNonRoot | bool | false | |
| postfix.service.public.externalTrafficPolicy | string | "Local" | |
| postfix.service.public.type | string | "LoadBalancer" | type of the public endpoint for smtp, submission, and submissions. Note: It’s configured to share the IP with dovecot in case of metallb |
| postfix.tls.secretName | string | "nil" | secret holding the TLS keys for postfix. Required |
| postfix.tolerations | list | [] | |
| postfix.volumes.spool.accessModes[0] | string | "ReadWriteOnce" | |
| postfix.volumes.spool.resources.requests.storage | string | "1Gi" | |
| relay.relayHosts | object | {} | relay hosts used as part of the deployment |
| relay.saslPasswords | object | {} | passwords for the relay hosts |
| relay.tlsPolicies | string | "" | tls policy in postfix https://www.postfix.org/TLS_README.html#client_tls_policy |
| serviceAccount.annotations | object | {} | |
| serviceAccount.create | bool | true | |
| serviceAccount.name | string | "" |
nextcloud
A file sharing server that puts the control and security of your own data back into your hands.
Introduction
This chart bootstraps an nextcloud deployment on a Kubernetes cluster using the Helm package manager.
Prerequisites
- Kubernetes 1.9+ with Beta APIs enabled
- PV provisioner support in the underlying infrastructure
- Helm >=3.7.0 (for subchart scope exposing)
- Own Database Operator or alike
Requirements
| Repository | Name | Version |
|---|---|---|
| https://charts.bitnami.com/bitnami | postgresql | 14.3.3 |
| https://charts.bitnami.com/bitnami | redis | 18.17.0 |
Installing the Chart
To install the chart with the release name my-release:
helm repo add nextcloud https://nextcloud.github.io/helm/
helm install my-release nextcloud/nextcloud
The command deploys nextcloud on the Kubernetes cluster in the default configuration. The configuration section lists the parameters that can be configured during installation.
Tip: List all releases using
helm list
Uninstalling the Chart
To uninstall/delete the my-release deployment:
helm delete my-release
The command removes all the Kubernetes components associated with the chart and deletes the release.
Values
| Key | Type | Default | Description |
|---|---|---|---|
| affinity | object | {} | |
| cronjob.annotations | object | {} | |
| cronjob.enabled | bool | false | |
| cronjob.failedJobsHistoryLimit | int | 5 | |
| cronjob.image | object | {} | |
| cronjob.schedule | string | "*/5 * * * *" | |
| cronjob.successfulJobsHistoryLimit | int | 2 | |
| deploymentAnnotations | object | {} | |
| externalDatabase.database | string | "nextcloud" | |
| externalDatabase.enabled | bool | false | |
| externalDatabase.existingSecret.enabled | bool | false | |
| externalDatabase.host | string | nil | |
| externalDatabase.password | string | nil | |
| externalDatabase.type | string | "mysql" | |
| externalDatabase.user | string | "nextcloud" | |
| fullnameOverride | string | "" | |
| hpa.cputhreshold | int | 60 | |
| hpa.enabled | bool | false | |
| hpa.maxPods | int | 10 | |
| hpa.minPods | int | 1 | |
| image.pullPolicy | string | "IfNotPresent" | |
| image.repository | string | "docker.io/library/nextcloud" | |
| ingress.annotations | object | {} | |
| ingress.enabled | bool | false | |
| ingress.labels | object | {} | |
| ingress.path | string | "/" | |
| ingress.pathType | string | "Prefix" | |
| internalDatabase.enabled | bool | true | |
| internalDatabase.name | string | "nextcloud" | |
| lifecycle | object | {} | |
| livenessProbe.enabled | bool | true | |
| livenessProbe.failureThreshold | int | 3 | |
| livenessProbe.initialDelaySeconds | int | 10 | |
| livenessProbe.periodSeconds | int | 10 | |
| livenessProbe.successThreshold | int | 1 | |
| livenessProbe.timeoutSeconds | int | 5 | |
| mariadb.architecture | string | "standalone" | |
| mariadb.auth.database | string | "nextcloud" | |
| mariadb.auth.password | string | "changeme" | |
| mariadb.auth.username | string | "nextcloud" | |
| mariadb.enabled | bool | false | |
| mariadb.primary.persistence.accessMode | string | "ReadWriteOnce" | |
| mariadb.primary.persistence.enabled | bool | false | |
| mariadb.primary.persistence.size | string | "8Gi" | |
| metrics.enabled | bool | false | |
| metrics.https | bool | false | |
| metrics.image.pullPolicy | string | "IfNotPresent" | |
| metrics.image.repository | string | "docker.io/xperimental/nextcloud-exporter" | |
| metrics.image.tag | string | "0.9.1" | |
| metrics.replicaCount | int | 1 | |
| metrics.service.annotations.“prometheus.io/port” | string | "9205" | |
| metrics.service.annotations.“prometheus.io/scrape” | string | "true" | |
| metrics.service.labels | object | {} | |
| metrics.service.type | string | "ClusterIP" | |
| metrics.serviceMonitor.enabled | bool | false | |
| metrics.serviceMonitor.interval | string | "30s" | |
| metrics.serviceMonitor.jobLabel | string | "" | |
| metrics.serviceMonitor.labels | object | {} | |
| metrics.serviceMonitor.namespace | string | "" | |
| metrics.serviceMonitor.scrapeTimeout | string | "" | |
| metrics.timeout | string | "5s" | |
| metrics.token | string | "" | |
| nameOverride | string | "" | |
| nextcloud.configs | object | {} | |
| nextcloud.datadir | string | "/var/www/html/data" | |
| nextcloud.defaultConfigs.“.htaccess” | bool | true | |
| nextcloud.defaultConfigs.“apache-pretty-urls.config.php” | bool | true | |
| nextcloud.defaultConfigs.“apcu.config.php” | bool | true | |
| nextcloud.defaultConfigs.“apps.config.php” | bool | true | |
| nextcloud.defaultConfigs.“autoconfig.php” | bool | true | |
| nextcloud.defaultConfigs.“redis.config.php” | bool | true | |
| nextcloud.defaultConfigs.“smtp.config.php” | bool | true | |
| nextcloud.existingSecret.enabled | bool | false | |
| nextcloud.extraEnv | string | nil | |
| nextcloud.extraInitContainers | list | [] | |
| nextcloud.extraVolumeMounts | string | nil | |
| nextcloud.extraVolumes | string | nil | |
| nextcloud.host | string | "nextcloud.kube.home" | |
| nextcloud.mail.domain | string | "domain.com" | |
| nextcloud.mail.enabled | bool | false | |
| nextcloud.mail.fromAddress | string | "user" | |
| nextcloud.mail.smtp.authtype | string | "LOGIN" | |
| nextcloud.mail.smtp.host | string | "domain.com" | |
| nextcloud.mail.smtp.name | string | "user" | |
| nextcloud.mail.smtp.password | string | "pass" | |
| nextcloud.mail.smtp.port | int | 465 | |
| nextcloud.mail.smtp.secure | string | "ssl" | |
| nextcloud.password | string | "changeme" | |
| nextcloud.persistence.subPath | string | nil | |
| nextcloud.phpConfigs | object | {} | |
| nextcloud.strategy.type | string | "Recreate" | |
| nextcloud.update | int | 0 | |
| nextcloud.username | string | "admin" | |
| nginx.config.default | bool | true | |
| nginx.enabled | bool | false | |
| nginx.image.pullPolicy | string | "IfNotPresent" | |
| nginx.image.repository | string | "nginx" | |
| nginx.image.tag | string | "alpine" | |
| nginx.resources | object | {} | |
| nodeSelector | object | {} | |
| persistence.accessMode | string | "ReadWriteOnce" | |
| persistence.annotations | object | {} | |
| persistence.enabled | bool | false | |
| persistence.nextcloudData.accessMode | string | "ReadWriteOnce" | |
| persistence.nextcloudData.annotations | object | {} | |
| persistence.nextcloudData.enabled | bool | false | |
| persistence.nextcloudData.size | string | "8Gi" | |
| persistence.nextcloudData.subPath | string | nil | |
| persistence.size | string | "8Gi" | |
| phpClientHttpsFix.enabled | bool | false | |
| phpClientHttpsFix.protocol | string | "https" | |
| podAnnotations | object | {} | |
| postgresql.enabled | bool | false | |
| postgresql.global.postgresql.auth.database | string | "nextcloud" | |
| postgresql.global.postgresql.auth.password | string | "changeme" | |
| postgresql.global.postgresql.auth.username | string | "nextcloud" | |
| postgresql.primary.persistence.enabled | bool | false | |
| rbac.enabled | bool | false | |
| rbac.serviceaccount.annotations | object | {} | |
| rbac.serviceaccount.create | bool | true | |
| rbac.serviceaccount.name | string | "nextcloud-serviceaccount" | |
| readinessProbe.enabled | bool | true | |
| readinessProbe.failureThreshold | int | 3 | |
| readinessProbe.initialDelaySeconds | int | 10 | |
| readinessProbe.periodSeconds | int | 10 | |
| readinessProbe.successThreshold | int | 1 | |
| readinessProbe.timeoutSeconds | int | 5 | |
| redis.auth.enabled | bool | true | |
| redis.auth.password | string | "changeme" | |
| redis.enabled | bool | false | |
| redis.image.repository | string | "bitnamilegacy/redis" | |
| replicaCount | int | 1 | |
| resources | object | {} | |
| runtimeClassName | string | nil | |
| service.loadBalancerIP | string | "nil" | |
| service.nodePort | string | "nil" | |
| service.port | int | 8080 | |
| service.type | string | "ClusterIP" | |
| startupProbe.enabled | bool | true | |
| startupProbe.failureThreshold | int | 600 | |
| startupProbe.periodSeconds | int | 10 | |
| startupProbe.successThreshold | int | 1 | |
| startupProbe.timeoutSeconds | int | 5 | |
| tolerations | list | [] |
| Parameter | Description | Default |
|---|---|---|
image.repository | nextcloud Image name | nextcloud |
image.flavor | nextcloud Image type | apache |
image.tag | nextcloud Image tag | {VERSION} |
image.pullPolicy | Image pull policy | IfNotPresent |
image.pullSecrets | Specify image pull secrets | nil |
ingress.className | Name of the ingress class to use | nil |
ingress.enabled | Enable use of ingress controllers | false |
ingress.servicePort | Ingress’ backend servicePort | http |
ingress.annotations | An array of service annotations | nil |
ingress.labels | An array of service labels | nil |
ingress.path | The Path to use in Ingress’ paths | / |
ingress.pathType | The PathType to use in Ingress’ paths | Prefix |
ingress.tls | Ingress TLS configuration | [] |
nextcloud.host | nextcloud host to create application URLs | nextcloud.kube.home |
nextcloud.username | User of the application | admin |
nextcloud.password | Application password | changeme |
nextcloud.existingSecret.enabled | Whether to use an existing secret or not | false |
nextcloud.existingSecret.secretName | Name of the existing secret | nil |
nextcloud.existingSecret.usernameKey | Name of the key that contains the username | nil |
nextcloud.existingSecret.passwordKey | Name of the key that contains the password | nil |
nextcloud.existingSecret.smtpUsernameKey | Name of the key that contains the SMTP username | nil |
nextcloud.existingSecret.smtpPasswordKey | Name of the key that contains the SMTP password | nil |
nextcloud.update | Trigger update if custom command is used | 0 |
nextcloud.containerPort | Customize container port when not running as root | 80 |
nextcloud.datadir | nextcloud data dir location | /var/www/html/data |
nextcloud.mail.enabled | Whether to enable/disable email settings | false |
nextcloud.mail.fromAddress | nextcloud mail send from field | nil |
nextcloud.mail.domain | nextcloud mail domain | nil |
nextcloud.mail.smtp.host | SMTP hostname | nil |
nextcloud.mail.smtp.secure | SMTP connection ssl or empty | '' |
nextcloud.mail.smtp.port | Optional SMTP port | nil |
nextcloud.mail.smtp.authtype | SMTP authentication method | LOGIN |
nextcloud.mail.smtp.name | SMTP username | '' |
nextcloud.mail.smtp.password | SMTP password | '' |
nextcloud.configs | Config files created in /var/www/html/config | {} |
nextcloud.persistence.subPath | Set the subPath for nextcloud to use in volume | nil |
nextcloud.phpConfigs | PHP Config files created in /usr/local/etc/php/conf.d | {} |
nextcloud.defaultConfigs.\.htaccess | Default .htaccess to protect /var/www/html/config | true |
nextcloud.defaultConfigs.redis\.config\.php | Default Redis configuration | true |
nextcloud.defaultConfigs.apache-pretty-urls\.config\.php | Default Apache configuration for rewrite urls | true |
nextcloud.defaultConfigs.apcu\.config\.php | Default configuration to define APCu as local cache | true |
nextcloud.defaultConfigs.apps\.config\.php | Default configuration for apps | true |
nextcloud.defaultConfigs.autoconfig\.php | Default auto-configuration for databases | true |
nextcloud.defaultConfigs.smtp\.config\.php | Default configuration for smtp | true |
nextcloud.strategy | specifies the strategy used to replace old Pods by new ones | type: Recreate |
nextcloud.extraEnv | specify additional environment variables | {} |
nextcloud.extraInitContainers | specify additional init containers | [] |
nextcloud.extraVolumes | specify additional volumes for the NextCloud pod | {} |
nextcloud.extraVolumeMounts | specify additional volume mounts for the NextCloud pod | {} |
nginx.enabled | Enable nginx (requires you use php-fpm image) | false |
nginx.image.repository | nginx Image name | nginx |
nginx.image.tag | nginx Image tag | alpine |
nginx.image.pullPolicy | nginx Image pull policy | IfNotPresent |
nginx.config.default | Whether to use nextclouds recommended nginx config | true |
nginx.config.custom | Specify a custom config for nginx | {} |
nginx.resources | nginx resources | {} |
lifecycle.postStartCommand | Specify deployment lifecycle hook postStartCommand | nil |
lifecycle.preStopCommand | Specify deployment lifecycle hook preStopCommand | nil |
internalDatabase.enabled | Whether to use internal sqlite database | true |
internalDatabase.database | Name of the existing database | nextcloud |
externalDatabase.enabled | Whether to use external database | false |
externalDatabase.type | External database type: mysql, postgresql | mysql |
externalDatabase.host | Host of the external database in form of host:port | nil |
externalDatabase.database | Name of the existing database | nextcloud |
externalDatabase.user | Existing username in the external db | nextcloud |
externalDatabase.password | Password for the above username | nil |
externalDatabase.existingSecret.enabled | Whether to use a existing secret or not | false |
externalDatabase.existingSecret.secretName | Name of the existing secret | nil |
externalDatabase.existingSecret.usernameKey | Name of the key that contains the username | nil |
externalDatabase.existingSecret.passwordKey | Name of the key that contains the password | nil |
mariadb.enabled | Whether to use the MariaDB chart | false |
mariadb.auth.database | Database name to create | nextcloud |
mariadb.auth.password | Password for the database | changeme |
mariadb.auth.username | Database user to create | nextcloud |
mariadb.auth.rootPassword | MariaDB admin password | nil |
postgresql.enabled | Whether to use the PostgreSQL chart | false |
postgresql.global.postgresql.auth.username | Database user to create | nextcloud |
postgresql.global.postgresql.auth.password | Password for the database | changeme |
postgresql.global.postgresql.auth.database | Database name to create | nextcloud |
postgresql.primary.persistence.enabled | Whether or not to use PVC on PostgreSQL primary | false |
redis.enabled | Whether to install/use redis for locking | false |
redis.auth.enabled | Whether to enable password authentication with redis | true |
redis.auth.password | The password redis uses | '' |
cronjob.enabled | Whether to enable/disable cronjob | false |
cronjob.schedule | Schedule for the CronJob | */15 * * * * |
cronjob.annotations | Annotations to add to the cronjob | {} |
cronjob.curlInsecure | Set insecure (-k) option to curl | false |
cronjob.failedJobsHistoryLimit | Specify the number of failed Jobs to keep | 5 |
cronjob.successfulJobsHistoryLimit | Specify the number of completed Jobs to keep | 2 |
cronjob.resources | Cronjob Resources | nil |
cronjob.nodeSelector | Cronjob Node selector | nil |
cronjob.tolerations | Cronjob tolerations | nil |
cronjob.affinity | Cronjob affinity | nil |
service.type | Kubernetes Service type | ClusterIP |
service.loadBalancerIP | LoadBalancerIp for service type LoadBalancer | nil |
service.nodePort | NodePort for service type NodePort | nil |
persistence.enabled | Enable persistence using PVC | false |
persistence.annotations | PVC annotations | {} |
persistence.storageClass | PVC Storage Class for nextcloud volume | nil (uses alpha storage class annotation) |
persistence.existingClaim | An Existing PVC name for nextcloud volume | nil (uses alpha storage class annotation) |
persistence.accessMode | PVC Access Mode for nextcloud volume | ReadWriteOnce |
persistence.size | PVC Storage Request for nextcloud volume | 8Gi |
persistence.nextcloudData.enabled | Create a second PVC for the data folder in nextcloud | false |
persistence.nextcloudData.annotations | see persistence.annotations | {} |
persistence.nextcloudData.storageClass | see persistence.storageClass | nil (uses alpha storage class annotation) |
persistence.nextcloudData.existingClaim | see persistence.existingClaim | nil (uses alpha storage class annotation) |
persistence.nextcloudData.accessMode | see persistence.accessMode | ReadWriteOnce |
persistence.nextcloudData.size | see persistence.size | 8Gi |
phpClientHttpsFix.enabled | Sets OVERWRITEPROTOCOL for https ingress redirect | false |
phpClientHttpsFix.protocol | Sets OVERWRITEPROTOCOL for https ingress redirect | https |
resources | CPU/Memory resource requests/limits | {} |
rbac.enabled | Enable Role and rolebinding for priveledged PSP | false |
rbac.serviceaccount.create | Wether to create a serviceaccount or use an existing one (requires rbac) | true |
rbac.serviceaccount.name | The name of the sevice account that the deployment will use (requires rbac) | nextcloud-serviceaccount |
rbac.serviceaccount.annotations | Serviceaccount annotations | {} |
livenessProbe.enabled | Turn on and off liveness probe | true |
livenessProbe.initialDelaySeconds | Delay before liveness probe is initiated | 10 |
livenessProbe.periodSeconds | How often to perform the probe | 10 |
livenessProbe.timeoutSeconds | When the probe times out | 5 |
livenessProbe.failureThreshold | Minimum consecutive failures for the probe | 3 |
livenessProbe.successThreshold | Minimum consecutive successes for the probe | 1 |
readinessProbe.enabled | Turn on and off readiness probe | true |
readinessProbe.initialDelaySeconds | Delay before readiness probe is initiated | 10 |
readinessProbe.periodSeconds | How often to perform the probe | 10 |
readinessProbe.timeoutSeconds | When the probe times out | 5 |
readinessProbe.failureThreshold | Minimum consecutive failures for the probe | 3 |
readinessProbe.successThreshold | Minimum consecutive successes for the probe | 1 |
startupProbe.enabled | Turn on and off startup probe | false |
startupProbe.initialDelaySeconds | Delay before readiness probe is initiated | 30 |
startupProbe.periodSeconds | How often to perform the probe | 10 |
startupProbe.timeoutSeconds | When the probe times out | 5 |
startupProbe.failureThreshold | Minimum consecutive failures for the probe | 30 |
startupProbe.successThreshold | Minimum consecutive successes for the probe | 1 |
hpa.enabled | Boolean to create a HorizontalPodAutoscaler | false |
hpa.cputhreshold | CPU threshold percent for the HorizontalPodAutoscale | 60 |
hpa.minPods | Min. pods for the Nextcloud HorizontalPodAutoscaler | 1 |
hpa.maxPods | Max. pods for the Nextcloud HorizontalPodAutoscaler | 10 |
deploymentLabels | Labels to be added at ‘deployment’ level | not set |
deploymentAnnotations | Annotations to be added at ‘deployment’ level | not set |
podLabels | Labels to be added at ‘pod’ level | not set |
podAnnotations | Annotations to be added at ‘pod’ level | not set |
metrics.enabled | Start Prometheus metrics exporter | false |
metrics.https | Defines if https is used to connect to nextcloud | false (uses http) |
metrics.token | Uses token for auth instead of username/password | "" |
metrics.timeout | When the scrape times out | 5s |
metrics.image.repository | Nextcloud metrics exporter image name | xperimental/nextcloud-exporter |
metrics.image.tag | Nextcloud metrics exporter image tag | 0.5.1 |
metrics.image.pullPolicy | Nextcloud metrics exporter image pull policy | IfNotPresent |
metrics.podAnnotations | Additional annotations for metrics exporter | not set |
metrics.podLabels | Additional labels for metrics exporter | not set |
metrics.service.type | Metrics: Kubernetes Service type | ClusterIP |
metrics.service.loadBalancerIP | Metrics: LoadBalancerIp for service type LoadBalancer | nil |
metrics.service.nodePort | Metrics: NodePort for service type NodePort | nil |
metrics.service.annotations | Additional annotations for service metrics exporter | {prometheus.io/scrape: "true", prometheus.io/port: "9205"} |
metrics.service.labels | Additional labels for service metrics exporter | {} |
metrics.serviceMonitor.enabled | Create ServiceMonitor Resource for scraping metrics using PrometheusOperator | false |
metrics.serviceMonitor.namespace | Namespace in which Prometheus is running | `` |
metrics.serviceMonitor.jobLabel | The name of the label on the target service to use as the job name in prometheus | `` |
metrics.serviceMonitor.interval | Interval at which metrics should be scraped | 30s |
metrics.serviceMonitor.scrapeTimeout | Specify the timeout after which the scrape is ended | `` |
metrics.serviceMonitor.labels | Extra labels for the ServiceMonitor | `{} |
Note:
For nextcloud to function correctly, you should specify the
nextcloud.hostparameter to specify the FQDN (recommended) or the public IP address of the nextcloud service.Optionally, you can specify the
service.loadBalancerIPparameter to assign a reserved IP address to the nextcloud service of the chart. However please note that this feature is only available on a few cloud providers (f.e. GKE).
Specify each parameter using the --set key=value[,key=value] argument to helm install. For example,
helm install --name my-release \
--set nextcloud.username=admin,nextcloud.password=password \
nextcloud/nextcloud
The above command sets the nextcloud administrator account username and password to admin and password respectively.
Alternatively, a YAML file that specifies the values for the above parameters can be provided while installing the chart. For example,
helm install --name my-release -f values.yaml nextcloud/nextcloud
Tip: You can use the default values.yaml
Persistence
The Nextcloud image stores the nextcloud data and configurations at the /var/www/html paths of the container.
Persistent Volume Claims are used to keep the data across deployments. This is known to work in GCE, AWS, and minikube. See the Configuration section to enable persistence and configuration of the PVC.
Cronjob
This chart can utilize Kubernetes CronJob resource to execute background tasks.
To use this functionality, set cronjob.enabled parameter to true and switch background mode to Webcron in your nextcloud settings page.
See the Configuration section for further configuration of the cronjob resource.
Note: For the cronjobs to work correctly, ingress must be also enabled (set
ingress.enabledtotrue) andnextcloud.hosthas to be publicly resolvable.
Multiple config.php file
Nextcloud supports loading configuration parameters from multiple files.
You can add arbitrary files ending with .config.php in the config/ directory.
See documentation.
For example, following config will configure Nextcloud with S3 as primary storage by creating file /var/www/html/config/s3.config.php:
nextcloud:
configs:
s3.config.php: |-
<?php
$CONFIG = array (
'objectstore' => array(
'class' => '\\OC\\Files\\ObjectStore\\S3',
'arguments' => array(
'bucket' => 'my-bucket',
'autocreate' => true,
'key' => 'xxx',
'secret' => 'xxx',
'region' => 'us-east-1',
'use_ssl' => true
)
)
);
Preserving Source IP
- Make sure your loadbalancer preserves source IP, for bare metal,
metalbdoes andklipper-lbdoesn’t. - Make sure your Ingress preserves source IP. If you use
ingress-nginx, add the following annotations:
ingress:
annotations:
nginx.ingress.kubernetes.io/enable-cors: "true"
nginx.ingress.kubernetes.io/cors-allow-headers: "X-Forwarded-For"
- The next layer is nextcloud pod’s nginx if you use
nextcloud-fpm, this can be left at default - Add some PHP config for nextcloud as mentioned above in multiple
config.phps section:
configs:
proxy.config.php: |-
<?php
$CONFIG = array (
'trusted_proxies' => array(
0 => '127.0.0.1',
1 => '10.0.0.0/8',
),
'forwarded_for_headers' => array('HTTP_X_FORWARDED_FOR'),
);
Hugepages
If your node has hugepages enabled, but you do not map any into the container, it could fail to start with a bus error in Apache. This is due to Apache attempting to memory map a file and use hugepages. The fix is to either disable huge pages on the node or map hugepages into the container:
nextcloud:
extraVolumes:
- name: hugepages
emptyDir:
medium: HugePages-2Mi
extraVolumeMounts:
- name: hugepages
mountPath: /dev/hugepages
resources:
requests:
hugepages-2Mi: 500Mi
# note that Kubernetes currently requires cpu or memory requests and limits before hugepages are allowed.
memory: 500Mi
limits:
# limit and request must be the same for hugepages. They are a fixed resource.
hugepages-2Mi: 500Mi
# note that Kubernetes currently requires cpu or memory requests and limits before hugepages are allowed.
memory: 1Gi
HPA (Clustering)
If you want to have multiple Nextcloud containers, regardless of dynamic or static sizes, you need to use shared persistence between the containers.
Minimum cluster compatible persistence settings:
persistence:
enabled: true
accessMode: ReadWriteMany
nut-exporter
Installs NUT exporter in Kubernetes
Homepage: https://github.com/DRuggeri/nut_exporter
Source Code
- https://git.shivering-isles.com/shivering-isles/infrastructure-gitops/-/tree/main/charts/nut-exporter
- https://github.com/DRuggeri/nut_exporter
- https://github.com/acolombier/nut_exporter/tree/feat/add-helm-chart
Values
| Key | Type | Default | Description |
|---|---|---|---|
| dashboard | object | {"enabled":true,"labels":{"grafana_dashboard":"1"}} | Deploys a Grafana dashboard as a configmap |
| env | list | [{"name":"NUT_EXPORTER_VARIABLES","value":"battery.charge,battery.runtime,battery.voltage,battery.voltage.nominal,input.voltage,input.voltage.nominal,ups.load,ups.status"},{"name":"NUT_EXPORTER_SERVER","value":"192.0.2.1"}] | environment variables for nut_exporter |
| extraArgs | list | [] | |
| image.pullPolicy | string | "IfNotPresent" | |
| image.repository | string | "ghcr.io/druggeri/nut_exporter" | |
| image.tag | string | "" | |
| nodeSelector | object | {} | |
| podMonitor | object | {"enabled":true,"labels":{},"params":{},"relabelings":[{"sourceLabels":["__param_ups"],"targetLabel":"ups"}]} | Enables podMonitor object for prometheus-operator based setups |
| podMonitor.params | object | {} | parameters that are used on the scrape target required for functional dashboard |
| podSecurityContext.runAsGroup | int | 3642 | |
| podSecurityContext.runAsNonRoot | bool | true | |
| podSecurityContext.runAsUser | int | 3642 | |
| podSecurityContext.seccompProfile.type | string | "RuntimeDefault" | |
| resources.limits.cpu | string | "200m" | |
| resources.limits.memory | string | "128Mi" | |
| resources.requests.cpu | string | "50m" | |
| resources.requests.memory | string | "24Mi" | |
| rules | object | `{“enabled”:true,“labels”:{},“rules”:[{“alert”:“UPSBatteryNeedsReplacement”,“annotations”:{“message”:“{{ $labels.ups }} is indicating a need for a battery replacement.”},“expr”:“network_ups_tools_ups_status{flag="RB"} != 0”,“for”:“60s”,“labels”:{“runbook_url”:“https://runbooks.s3.shivering-isles.com/runbooks/nut-exporter/upsbatteryneedsreplacement/”,“severity”:“high”}},{“alert”:“UPSLowBattery”,“annotations”:{“message”:“{{ $labels.ups }} has low battery and is running on backup. Expect shutdown soon”},“expr”:“network_ups_tools_ups_status{flag="LB"} == 0 and network_ups_tools_ups_status{flag="OL"} == 0”,“for”:“60s”,“labels”:{“runbook_url”:“https://runbooks.s3.shivering-isles.com/runbooks/nut-exporter/upslowbattery/”,“severity”:“critical”}},{“alert”:“UPSRuntimeShort”,“annotations”:{“message”:“{{ $labels.ups }} has only {{ $value | humanizeDuration}} of battery autonomy“},“expr”:“network_ups_tools_battery_runtime < 300”,“for”:“30s”,“labels”:{“runbook_url”:“https://runbooks.s3.shivering-isles.com/runbooks/nut-exporter/upsruntimeshort/”,“severity”:“high”}},{“alert”:“UPSMainPowerOutage”,“annotations”:{“message”:“{{ $labels.ups }} has no main power and is running on backup.”},“expr”:“network_ups_tools_ups_status{flag="OL"} == 0”,“for”:“60s”,“labels”:{“runbook_url”:“https://runbooks.s3.shivering-isles.com/runbooks/nut-exporter/upsmainpoweroutage/”,“severity”:“critical”}},{“alert”:“UPSIndicatesWarningStatus”,“annotations”:{“message”:“{{ $labels.ups }} is indicating a need for a battery replacement.”},“expr”:“network_ups_tools_ups_status{flag="HB"} != 0”,“for”:“60s”,“labels”:{“runbook_url”:“https://runbooks.s3.shivering-isles.com/runbooks/nut-exporter/upsindicateswarningstatus/”,“severity”:“warning”}}]}` |
| securityContext.allowPrivilegeEscalation | bool | false | |
| securityContext.capabilities.drop[0] | string | "ALL" | |
| securityContext.readOnlyRootFilesystem | bool | true | |
| serviceAccount.annotations | object | {} | Annotations to add to the service account |
| serviceAccount.create | bool | true | Specifies whether a service account should be created |
| serviceAccount.name | string | "" | The name of the service account to use. If not set and create is true, a name is generated using the fullname template |
| tolerations | list | [] |
findmydevice
A Helm chart for the findmydevice (FMD) server. A project for Android and linux that allows “Find my Phone”-functionality as known from Apple and Google, without handing data over to them.
Homepage: https://gitlab.com/fmd-foss/fmd-server
Source Code
- https://gitlab.com/fmd-foss/fmd-server
- https://git.shivering-isles.com/shivering-isles/infrastructure-gitops/-/tree/main/charts/findmydevice
Values
| Key | Type | Default | Description |
|---|---|---|---|
| affinity | object | {} | |
| fullnameOverride | string | "" | |
| image.pullPolicy | string | "IfNotPresent" | Pull policy allows to configure whether an image should be used if already on the host or pulled freshly regardless. |
| image.repository | string | "registry.gitlab.com/fmd-foss/fmd-server" | Container registry image to use |
| image.tag | string | "" | Overrides the image tag whose default is the chart appVersion. |
| imagePullSecrets | list | [] | |
| ingress.annotations.“nginx.ingress.kubernetes.io/client-body-buffer-size” | string | "20M" | |
| ingress.annotations.“nginx.ingress.kubernetes.io/proxy-body-size” | string | "20M" | |
| ingress.className | string | "" | |
| ingress.enabled | bool | false | |
| ingress.hosts[0].host | string | "chart-example.local" | |
| ingress.hosts[0].paths[0].path | string | "/" | |
| ingress.hosts[0].paths[0].pathType | string | "ImplementationSpecific" | |
| ingress.tls | list | [] | |
| nameOverride | string | "" | |
| nodeSelector | object | {} | |
| persistentVolumeClaim.accessMode | string | "ReadWriteOnce" | Volume Access mode, ReadWriteOnce is recommended |
| persistentVolumeClaim.size | string | "20Gi" | Requested Volume size of the PVC |
| persistentVolumeClaim.storageClass | string | nil | Storage class used for objectbox database |
| podAnnotations | object | {} | |
| podSecurityContext.fsGroup | int | 65532 | Sets the filesystem permissions. Since the application requires the data directory to be owned by uid 65532. Note: if you use the non-distroless image, change this to 1000 |
| resources.limits.cpu | string | "1" | |
| resources.limits.memory | string | "512Mi" | |
| resources.requests.cpu | string | "200m" | |
| resources.requests.memory | string | "256Mi" | |
| securityContext.allowPrivilegeEscalation | bool | false | |
| securityContext.capabilities.drop[0] | string | "ALL" | |
| securityContext.runAsNonRoot | bool | true | Enforces that the application can’t run as root |
| securityContext.runAsUser | int | 65532 | Starts the application as uid 65532 Note: if you use the non-distroless image, change this to 1000 |
| securityContext.seccompProfile.type | string | "RuntimeDefault" | |
| service.port | int | 80 | |
| service.type | string | "ClusterIP" | |
| serviceAccount.annotations | object | {} | Annotations to add to the service account |
| serviceAccount.create | bool | true | Specifies whether a service account should be created |
| serviceAccount.name | string | "" | The name of the service account to use. If not set and create is true, a name is generated using the fullname template |
| tolerations | list | [] |
Images
Overview over images that are maintained as part of the GitOps infrastructure repository.
cowsay
_________________________________________
/ This is the cowsay image. It a \
| distroless based image for cowsay, |
| allowing to use cowsay in any OCI |
| compatible container environment with |
| as little overhead as possible. |
| |
| You feel like you need cow to tell you |
| something? No problem, just `podman run |
| --rm -it quay.io/shivering-isles/cowsay |
| "Something"`. We'll provide you with a |
| cow telling you something, as quick as |
\ possible! /
-----------------------------------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
Building
_________________________________________
/ This cowsay container uses earthly to \
| build. Therefore in order to build, |
| please checkout https://earthly.dev. |
| Once you have earthly installed, you |
| can just run `earthly |
| git.shivering-isles.com/shivering-isles |
| /infrastructure-gitops/images/cowsay+co |
| ntainer`. |
| |
| I agree, it's quite a mouth full, but |
| just keep chewing on it! You can make |
| your own cows this way! |
| |
| Oh, and if you already cloned the |
| repository, it's just `earthly |
\ ./images/cowsay+container`. /
-----------------------------------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
References
_________________________________________
/ This image is based on cowsay from the \
| cowsay organisation. Means it's |
| officially in perl. |
| |
| You can find them at: |
| https://github.com/cowsay-org/cowsay/ |
| |
| They are a nice herd, so be friendly. |
| |
| Also a shoutout to Scott Williams who |
| started this mayhem with distroless |
| cows! |
| |
| https://mastodon.online/@vwbusguy/11130 |
\ 9874085945955 /
-----------------------------------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
License
_________________________________________
/ The content of this directory is \
| licensed under the same license as the |
| official cowsay project. At the time of |
| writing this is GPL-3.0 license. |
| |
| The current reference to the upstream |
| license is: |
| https://github.com/cowsay-org/cowsay/bl |
\ ob/v3.7.0/LICENSE.txt /
-----------------------------------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
dovecot
Simple dovecot container, build with the intend to be used in combination with Kubernetes. This means the image on its own might not be useful. It doesn’t come with external database backend.
References
This image is heavily inspired by https://github.com/mum-project/docker-images/tree/master/postfix
Jellyfin PDB Manager
The Jellyfin PodDisruptionBudget (PDB) Manager is a small go project that can run as sidecar along with Jellyfin and automatically configures the Jellyfin PDB to block or unblock depending on sessions that are watching something.
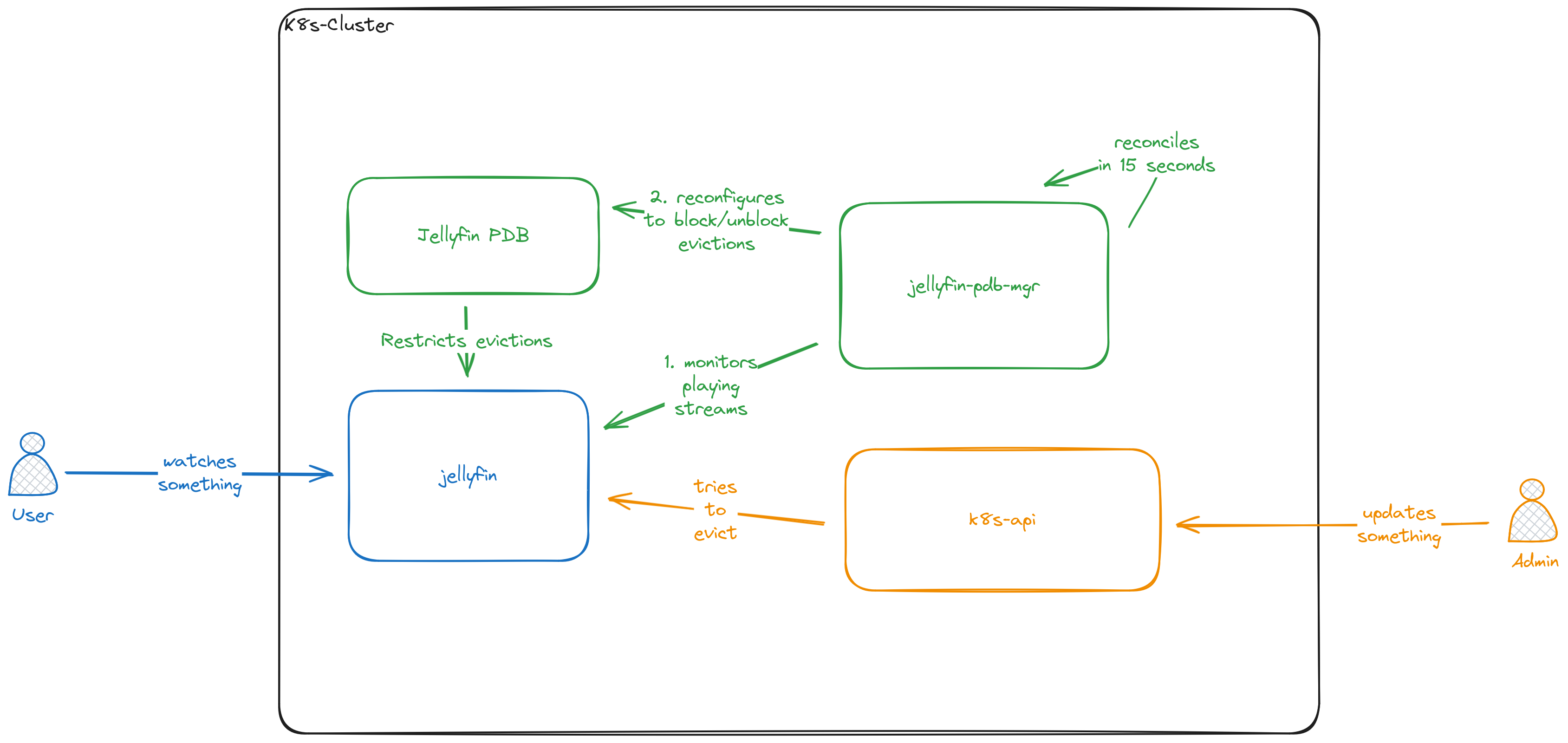
This simple construct integrates Jellyfin with Kubernetes allowing graceful handling of updates, making sure that draining of a node is blocked until you finished watching your show.
Limitations: this doesn’t prevent deletion or updates of the Jellyfin Pods itself, it just prevents certain voluntary disruptions.
Koolbox
A mashup of various tools in a box to be a Kubernetes Toolbox, basically a K-oolbox. It provides basically all tools one needs to administrate Kubernetes clusters and simply runs itself as a container on your system using podman.
It follows the XDG_*-standards to isolate its configuration. It is built to not mess with your system config, means no shared .ssh, .gnupg or alike. What happens in the koolbox, stays in the koolbox.
Requirements
Have podman installed. And in best case running Fedora Workstation or Silverblue.
Installation
Run earthly ./+install. And if you want to build the container locally run earthly ./+container.
Usage
Switch to the gitops directory and run the command koolbox and you’ll end up in the koolbox environment.
Motivation
The container and Kubernetes ecosystem is switching its toolchain quite quickly. As a result these tools are all litered across the workstation. To make things worse, a lot of these tools are not properly packaged and therefore not signed or verified in any way. Not necessarily something you want to let loose on your home directory. The idea with koolbox is to keep the Kubernetes tools confied and easily removable using just containers.
Ideas & ToDos
- Move secrets into the system secret store using
secret-tool - Store secrets in
pass - Figure out how to properly pass smartcards & gnupg in general into the koolbox container
- Make CLI more universal for non-Fedora systems
Postfix
Postfix container image intended for use in Kubernetes with plain text user backend.
This container image is kept minimal and all configs are supplied as part of the MoK Helm chart.
Expectations
| Path | Usage |
|---|---|
/srv/virtual | All files for virtual hosting (domains, aliases, mailboxes) |
/srv/tls/ | TLS key and certificate used for TLS enabled services |
References
This image is heavily inspired by https://github.com/mum-project/docker-images/tree/master/postfix
Synadm
Simple container providing the synadm CLI with nicely isolated from the system.
Requirements
Have podman installed. And in best case running Fedora Workstation or Silverblue.
Installation
In order to install it, you just build the container yourself and get a neat little shell script installed in ~/bin/
earthly +install
synadm --help